Chapter 4 Statistique bivariée
Ce chapitre s’intéresse aux analyses statistiques que l’on peut produire lorsqu’on s’intéresse à la liaison entre 2 variables observées sur les mêmes individus. Dire qu’il existe une liaison entre deux variables signifie que l’on peut décrire ou mesurer l’effet que le comportement de l’une induit sur celui de l’autre variable. On parle aussi de lien ou d’association entre deux variables. Selon la nature de chacune des deux variables, on sera amené à utiliser des indicateurs statistiques et représentations graphiques adaptés.
4.1 Deux variables quantitatives
Nuage de points 2D
Données économiques
Les organismes de micro-financement (OMF) jouent un rôle économique important dans le développement de l’économie locale des pays émergeants. La caractérisation de ces organismes est un enjeu important. Les données sont disponibles en ligne à l’adresse
https://www.math.univ-toulouse.fr/~ferraty/DATA/micro_finance.csv.
Ce tableau de données contient 492 lignes (1 ligne = 1 OMF) et 18 colonnes. Les 8 premières variables concernent différentes caractéristiques catégorielles ; les variables 9 à 14 portent sur des caractéristiques économiques quantitatives ; la variable quantitative 15 est un indicateur d’efficience (plus cet indicateur est faible, plus l’organisme est efficient). Au final, on observe pour chaque organisme de micro-financement 8 variables catégorielles (numérotées de 1 à 8) et 7 variables quantitatives (numérotées de 9 à 15) : Country, Region (Africa / East Asia and the Pacific / Eastern Europe and Central Asia / Latin America and The Caribbean / South Asia), Age (Mature / Young / New), Current legal status (Bank / Credit-Union-Cooperative / NBFI / NGO / Rural Bank), Financial Intermediation (High FI / Low FI), Profit status (Non-profit / Profit), Regulated (no / yes), Scale (Large / Medium / Small), Assets, Personnel expense / assets, Number of active borrowers, Number of depositors, Personnel expense, Nb of Personnel, Efficience (indicateur économique évaluant la bonne santé d’une entreprise)
Importation des données.
Exercice 4.1 Une fois le fichier téléchargé, importer les données dans votre session R en utilisant la fonctionnalité “Import Dataset” de RStudio (sans oublier de cocher l’option “stringsAsFactors”). Vous créerez un objet R appelé MICFIN qui contiendra l’ensemble de ces données. Visualisez ces données puis afficher son résumé.
Pré-traitement des données
Il est parfois avantageux de transformer des variables quantitatives avant de les étudier. C’est souvent le cas pour des variables quantitatives en économie.
Pour s’en convaincre, comparons les histogrammes des deux variables quantitatives brutes
avec ceux construits à partir des mêmes variables transformées à l’aide de la fonction logarithmique :
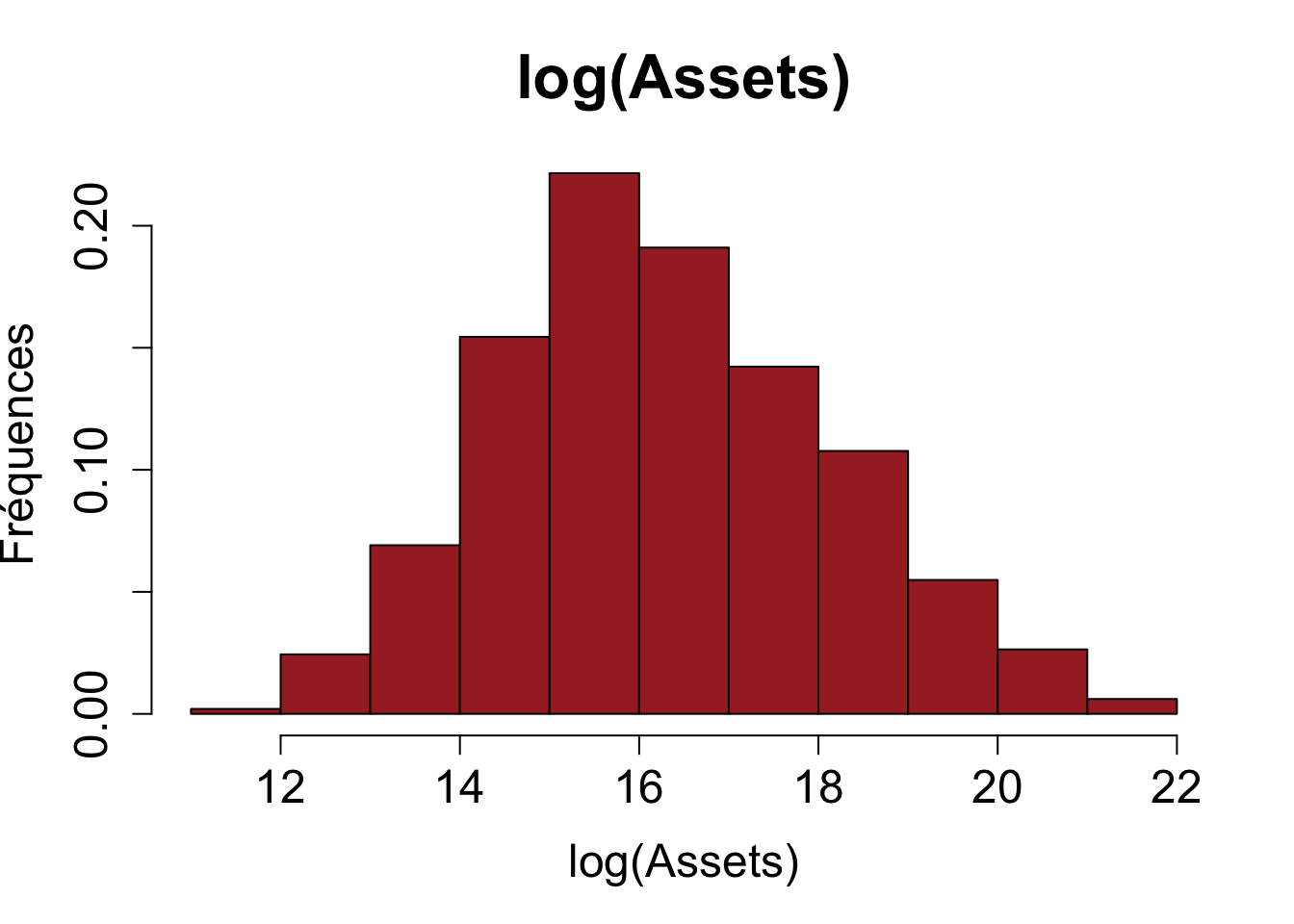
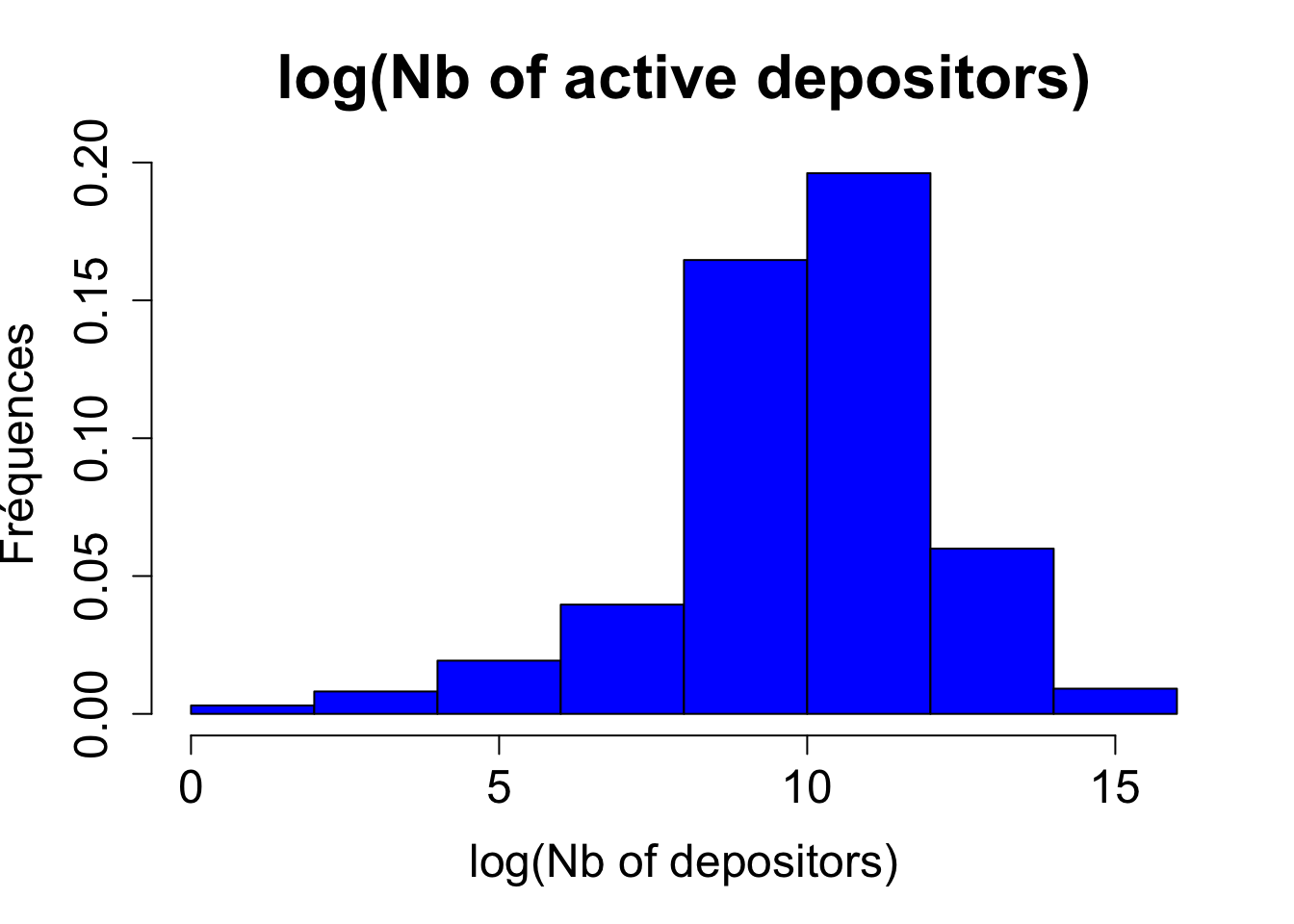
L’avantage de transformer les variables initiales à l’aide de la fonction logarithmique est de permettre une description plus précise de la distribution des valeurs observées. On va donc appliquer une transformation logarithmique sur les variables quantitatives correspondant aux colonnes 9 à 15 (on ne change pas les 8 premières colonnes qui correspondent aux variables catégorielles)
puis on modifie les noms des variables ainsi transformées (toujours positionnées sur les colonnes 9 à 15) :
colnames(MICFINLOG)[9:15] = c("logAssets", "logPersonnel.expense.to.assets", "logNb.active.borrowers", "logNb.depositors", "logPersonnel.expense", "logPersonnel", "logEfficience")Rappel : par principe, on s’efforce d’affecter des noms de variables qui identifient au mieux leur contenu.
Relation entre logAssets et logPersonnel.expense
On s’intéresse à la description de la relation qui peut exister entre la variable qui contient les logarithmes des actifs des OMF et celle qui mesure les logarithmes des dépenses relatives au personnel. Le nuage de points est l’outil graphique qui permet de réaliser cet objectif :
plot(MICFINLOG[, 9], MICFINLOG[, 13], xlab = "log(Assets)", ylab = "log(Personnel expenses)", main = "Nuage de points : log(Assets) vs log(Personnel expenses)")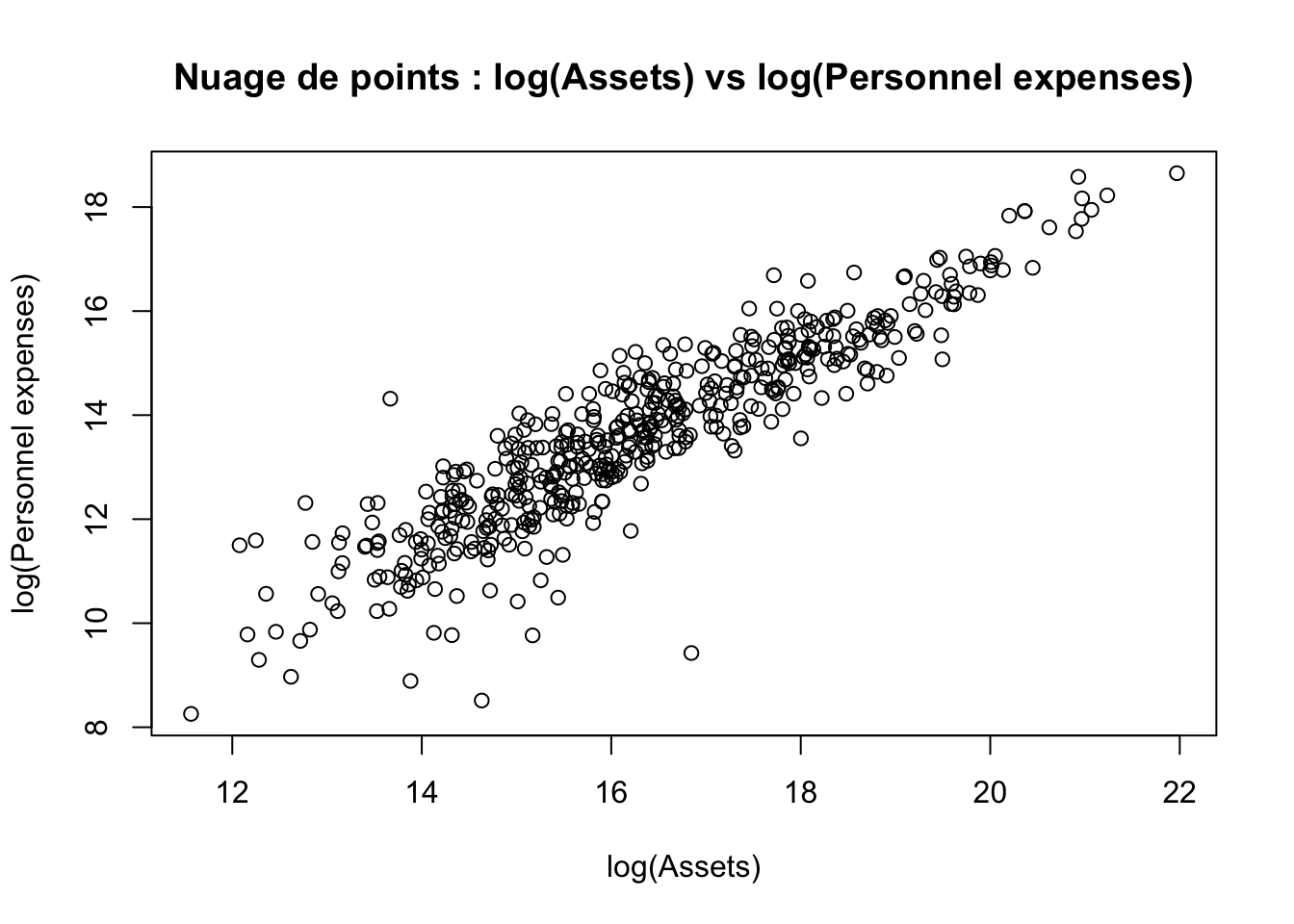
Commentaires sur le nuage de points :
l’allure générale du nuage de points est très allongée ; on parle de forme rectiligne
En moyenne, lorsque les log des actifs des OMF augmentent, les log des dépenses relatives au personnel augmentent aussi et vice-versa. Autrement dit, le sens de variation est le même pour ces 2 variables
Pour rappel, le coefficient de corrélation linéaire mesure l’intensité d’une relation linéaire entre 2 variables ; cet indicateur est compris entre -1 et 1. Les 2 variables possédant le même sens de variation, on peut dire sans le calculer que le coefficient de corrélation est positif. La forte colinéarité remarquée dans ce nuage de points indique que le coefficient de corrélation est élevé (proche de 1).
Pour confirmer cette interprétation, on peut calculer le coefficient de corrélation linéaire à l’aide de la commande :
qui fournit le résultat
[1] 0.9094476Sa valeur étant égale à 0.91, elle est bien positive et très élevée car proche de 1.
Exercice 4.2 Répondez aux questions suivantes :
Représenter le nuage de points entre le log des actifs et le log du nombre d’emprunteurs.
À partir de la forme du nuage de points, quel est le signe de la corrélation linéaire entre ces 2 variables?
À votre avis, cette corrélation linéaire sera-t-elle plus grande ou plus petite que celle mesurant le lien entre le logarithme des actifs et le logarithme des dépenses relatives au personnel?
Calculer le coefficient de corrélation linéaire.
Exercice 4.3 Trouver une variable pour laquelle la corrélation avec le log des actifs est proche de zéro puis représenter le nuage de point.
Droite de régression
Rappel : lorsqu’on dispose de deux variables \(X\) et \(Y\) observées sur \(n\) individus, on dispose de \(n\) couples de valeurs \((x_1, y_1), (x_2, y_2),...,(x_n, y_n)\).La droite de régression correspond à la droite d’équation \(y = \hat{a} \, x + \hat{b}\) où \(\hat{a}\) et \(\hat{b}\) sont obtenus en minimisant par rapport à \(a\) et \(b\) la somme des carrés \((y_1 - a x_1 - b)^2 + \cdots + (y_n - a x_n - b)^2\).
Utilisons la fonction R lm (abréviation de linear model) qui permet de tracer la droite de régression. Pour cela, on crée (voir la section Dataframe : une structure de données très utile du chapitre Introduction à R et RStudio) un dataframe à l’aide de la fonction R data.frame
Une fois le dataframe (nommé ici df) créé, on peut utiliser la fonction lm qui calcule la droite de régression :
La colonne ‘Estimate’ contient \(\hat{b} \simeq -0.775\) (Intercept) et \(\hat{a} \simeq 0.884\) (x). Une fois que la droite de régression a été calculée, on peut représenter le nuage des points puis la droite de régression à l’aide de la fonction abline() :
plot(df$x, df$y, xlab = "log of assets", ylab ="log of personnel expense", main = "Droite de régression : 'log of assets' vs 'log of personnel expense'")
abline(reglin1, col = "blue", lwd = 4)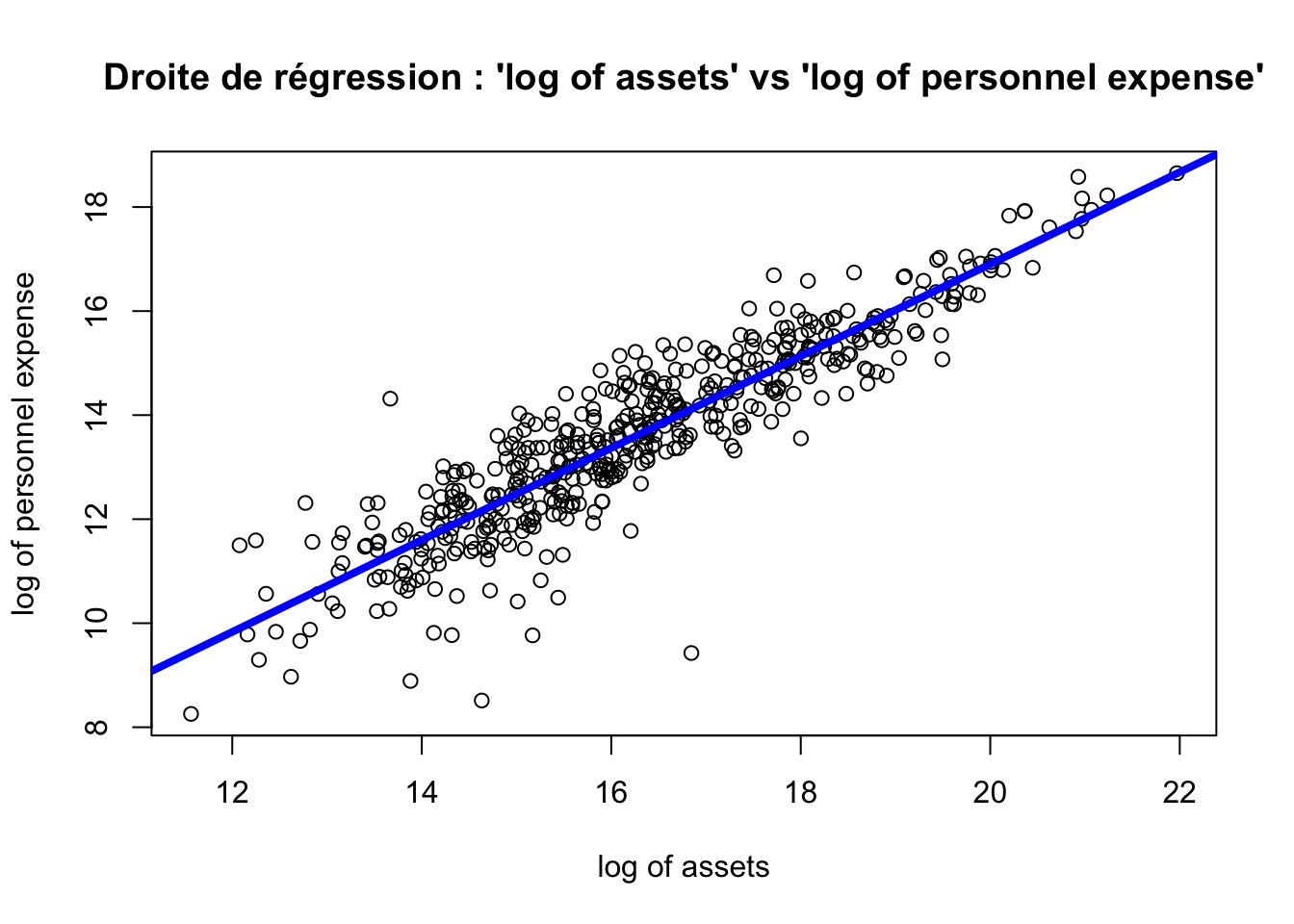
On peut dire ici que la doite de régression ajuste bien le nuage de points ou encore que la droite de régression résume assez bien le nuage des points.
Exercice 4.4 Tracer la droite de régression sur le nuage de points décrivant la relation entre les actifs des OMF et le nombre d’emprunteurs ; l’ajustement du nuage de points est-il meilleur que précédemment (log of assets et log of personnel expense)?
Budget de l’état français de 1872 à 1971
On s’intéresse maintenant aux différents postes de dépense de l’État français de 1872 à 1971 et plus particulièrement aux pourcentages du budget global pour éliminer l’effet de l’inflation et de l’évolution de la valeur nominale du franc sur cette période. Les postes de dépense sont notés PVP (pouvoirs publics), AGR (agriculture), CMI (commerce et industrie), TRA (travail), LOG (logement), EDU (éducation), ACS (action sociale), ANC (anciens combattants), DEF (défense), DET (remboursement de la dette), DIV (divers). Trois variables sont catégorielles (AGR, DEF et LOG) c’est-à-dire que leurs modalités expriment des catégories alors que les huit autres variables sont purement quantitatives. Le fichier “budget_etat_1872_1971.csv” accessible à l’adresse
http://www.math.univ-toulouse.fr/~ferraty/DATA/budget_etat_1872_1971.csv
contient les données suivantes :| PVP | AGR | CMI | TRA | LOG | EDU | ACS | ANC | DEF | DET | DIV | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1872 | 18.0 | <=1% | 0.1 | 6.7 | <=1.4% | 2.1 | 2.0 | 0.0 | 20%-35% | 41.5 | 2.1 |
| 1880 | 14.1 | <=1% | 0.1 | 15.3 | >1.4% | 3.7 | 0.5 | 0.0 | 20%-35% | 31.3 | 2.5 |
| 1890 | 13.6 | <=1% | 0.7 | 6.8 | <=1.4% | 7.1 | 0.7 | 0.0 | 20%-35% | 34.4 | 1.7 |
| 1900 | 14.3 | 1%-2% | 1.7 | 6.9 | <=1.4% | 7.4 | 0.8 | 0.0 | >35% | 26.2 | 2.2 |
| 1903 | 10.3 | 1%-2% | 0.4 | 9.3 | <=1.4% | 8.5 | 0.9 | 0.0 | >35% | 27.2 | 3.0 |
| 1906 | 13.4 | 1%-2% | 0.5 | 8.1 | <=1.4% | 8.6 | 1.8 | 0.0 | >35% | 25.3 | 1.9 |
| 1909 | 13.5 | 1%-2% | 0.5 | 9.0 | <=1.4% | 9.0 | 3.4 | 0.0 | >35% | 23.5 | 2.6 |
| 1912 | 12.9 | 1%-2% | 0.3 | 9.4 | <=1.4% | 9.3 | 4.3 | 0.0 | >35% | 19.4 | 1.3 |
| 1920 | 12.3 | <=1% | 0.1 | 11.9 | >1.4% | 3.7 | 1.7 | 1.9 | >35% | 23.1 | 0.2 |
| 1923 | 7.6 | 1%-2% | 3.2 | 5.1 | <=1.4% | 5.6 | 1.8 | 10.0 | 20%-35% | 35.0 | 0.9 |
| 1926 | 10.5 | <=1% | 0.4 | 4.5 | >1.4% | 6.6 | 2.1 | 10.1 | <=20% | 41.6 | 2.3 |
| 1929 | 10.0 | <=1% | 0.6 | 9.0 | <=1.4% | 8.1 | 3.2 | 11.8 | 20%-35% | 25.8 | 2.0 |
| 1932 | 10.6 | <=1% | 0.3 | 8.9 | >1.4% | 10.0 | 6.4 | 13.4 | 20%-35% | 19.2 | 0.0 |
| 1935 | 8.8 | >2% | 1.4 | 7.8 | <=1.4% | 12.4 | 6.2 | 11.3 | 20%-35% | 18.5 | 0.4 |
| 1938 | 10.1 | 1%-2% | 1.2 | 5.9 | <=1.4% | 9.5 | 6.0 | 5.9 | >35% | 18.2 | 0.0 |
| 1947 | 15.6 | 1%-2% | 10.1 | 11.4 | >1.4% | 8.8 | 4.8 | 3.4 | 20%-35% | 4.6 | 0.0 |
| 1950 | 11.2 | 1%-2% | 16.5 | 12.4 | >1.4% | 8.1 | 4.9 | 3.4 | 20%-35% | 4.2 | 1.5 |
| 1953 | 12.9 | 1%-2% | 7.0 | 7.9 | >1.4% | 8.1 | 5.3 | 3.9 | >35% | 5.2 | 0.0 |
| 1956 | 10.9 | >2% | 9.7 | 7.6 | >1.4% | 9.4 | 8.5 | 4.6 | 20%-35% | 6.2 | 0.0 |
| 1959 | 13.1 | >2% | 7.3 | 5.7 | >1.4% | 12.5 | 8.0 | 5.0 | 20%-35% | 7.5 | 0.0 |
| 1962 | 12.8 | >2% | 7.5 | 6.6 | >1.4% | 15.7 | 9.7 | 5.3 | 20%-35% | 6.4 | 0.1 |
| 1965 | 12.4 | >2% | 8.4 | 9.1 | >1.4% | 19.5 | 10.6 | 4.7 | <=20% | 3.5 | 1.8 |
| 1968 | 11.4 | >2% | 9.5 | 5.9 | >1.4% | 21.1 | 10.7 | 4.2 | <=20% | 4.4 | 1.9 |
| 1971 | 12.8 | >2% | 7.1 | 8.5 | >1.4% | 23.8 | 11.3 | 3.7 | <=20% | 7.2 | 0.0 |
Ici, les « individus » sont les années, et les variables précisent la part des différents postes de dépense dans le budget l’état français.
Exercice 4.5 Tracer la droite de régression (en créant l’objet reglin3) sur le nuage de points décrivant la relation entre ACS (action sociale) et EDU (éducation). Commentez le graphique.
Rajouter de l’information sur un graphique
Afficher les labels des individus
Il peut être informatif de rajouter les labels des individus. La fonction text() permet cette fonctionnalité :
plot(BUDGET$ACS, BUDGET$EDU, xlab = "Part action sociale", ylab ="Part éducation", main = "Droite de régression : 'Part action sociale' vs 'Part éducation'")
abline(reglin3, col = "blue", lwd =4)
text(BUDGET$ACS, BUDGET$EDU, labels = rownames(BUDGET), cex = 0.8, pos = 3)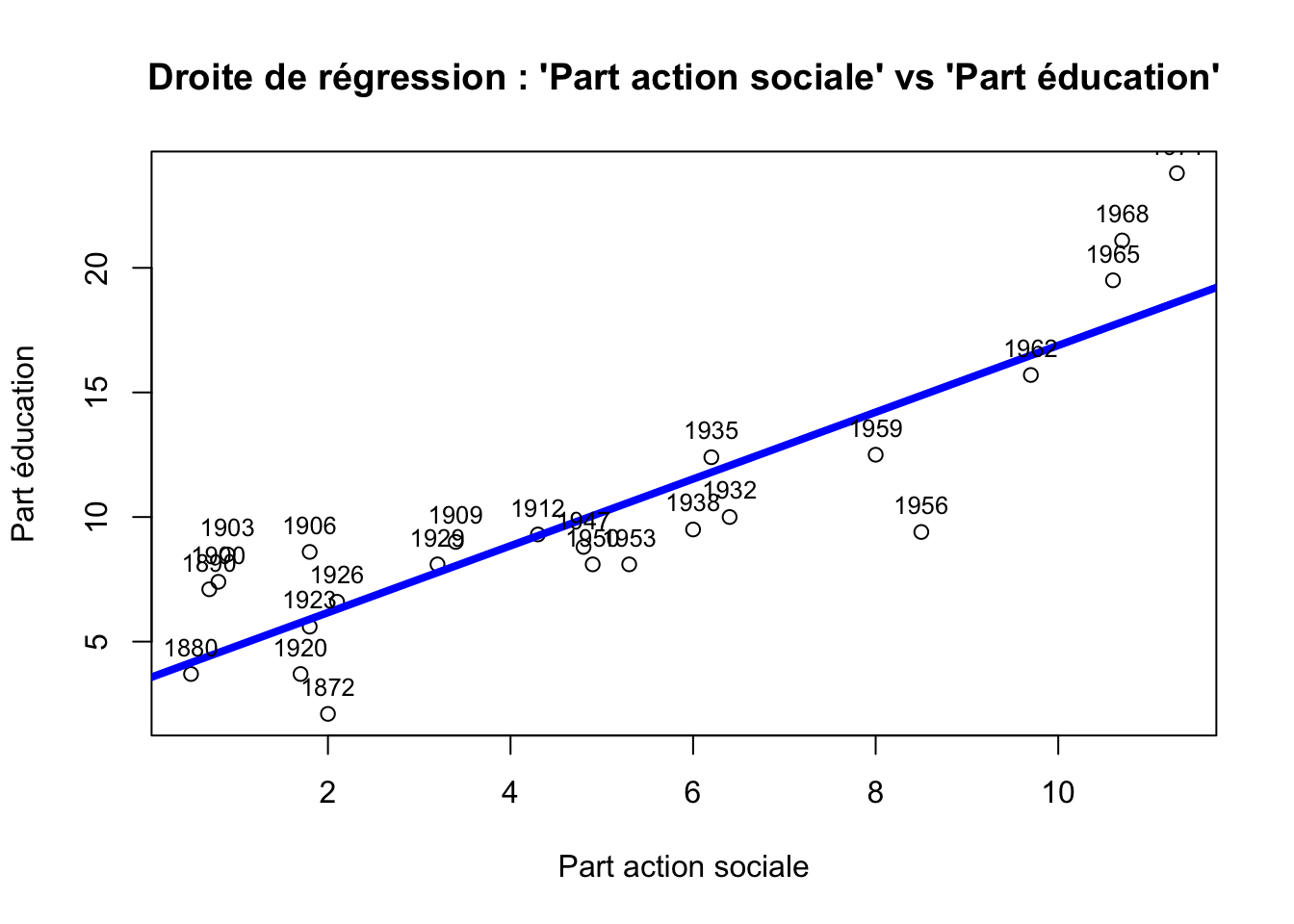
Certaines années, voire périodes, se situent au-dessus de la droite de régression. Cela signifie que la part de budget consacré à l’éducation est un peu plus importante relativement à la part que représente l’action sociale dans le budget de l’état français. Le commentaire inverse peut être fait pour les années situées en dessous de la droite de régression.
Colorier le nuage de points selon une variable catégorielle
plot(BUDGET$ACS, BUDGET$EDU, col = BUDGET$AGR, xlab = "part budget action sociale", ylab = "part budget éducation", main = "Nuage de points : ACS vs EDU coloré selon les modalités de AGR")
text(BUDGET$ACS, BUDGET$EDU, labels = rownames(BUDGET), cex = 1, pos = 3, col = as.numeric(BUDGET$AGR))
legend('bottomright', legend = levels(BUDGET$AGR), col = 1:3, cex = 1, pch = 1)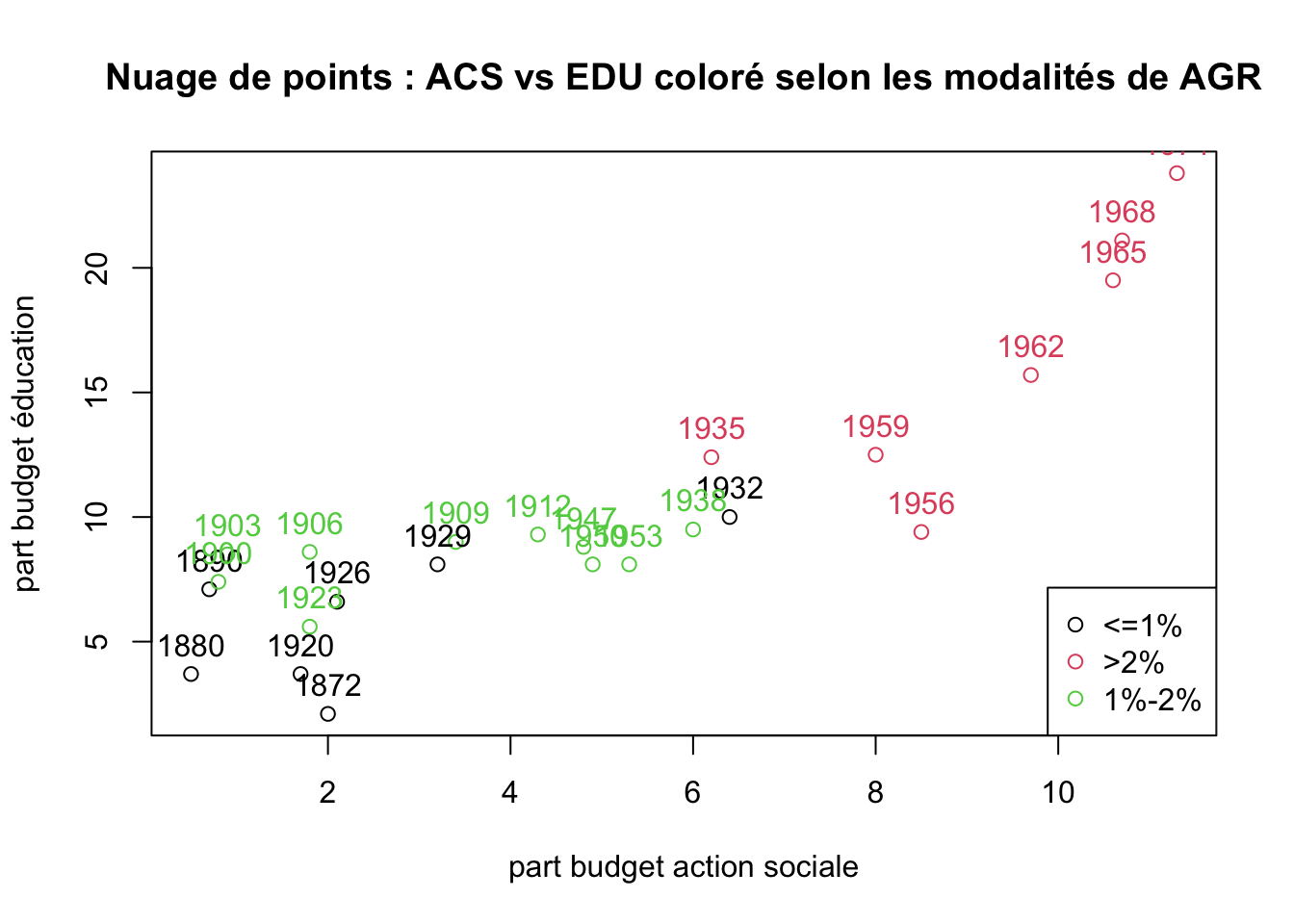
Remarque : en comparant BUDGET$AGR
[1] <=1% <=1% <=1% 1%-2% 1%-2% 1%-2% 1%-2% 1%-2% <=1% 1%-2% <=1% <=1%
[13] <=1% >2% 1%-2% 1%-2% 1%-2% 1%-2% >2% >2% >2% >2% >2% >2%
Levels: <=1% >2% 1%-2%et as.numeric(BUDGET$AGR)
[1] 1 1 1 3 3 3 3 3 1 3 1 1 1 2 3 3 3 3 2 2 2 2 2 2on voit que le 1er niveau “<=1%” du facteur AGR est codé par 1, le 2ème “>2%” par 2 et le 3ème “1%-2%” par 3, les premiers entiers définissant des couleurs par défaut.
Commentaire : on peut remarquer que la part de budget alloué à l’agriculture est plus importante sur les dates les plus récentes (à partir de 1956). Cela correspond au développement du modèle de culture intensive.
4.2 Deux variables catégorielles
Données sur le naufrage du Titanic
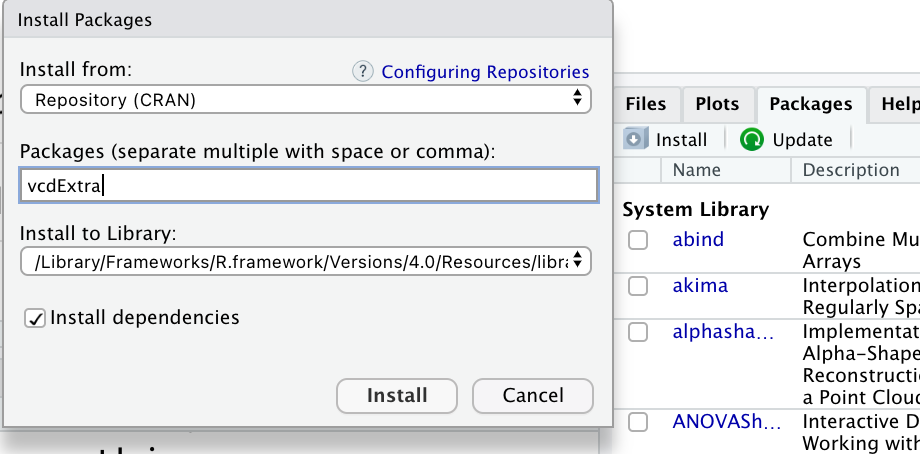
Considérons dans ce paragraphe les données sur le naufrage du paquebot Titanic. Les données sont contenues dans un dataframe appelé Titanicp et disponible dans le package vcdExtra. On récupère ce jeu de données en chargeant le package vcdExtra dans votre session R à l’aide de la commande
Loading required package: vcdLoading required package: gridLoading required package: gnmRemarque : si cette commande ne fonctionne pas, il est possible que le package vcdExtra ne soit pas installé. Dans ce cas, son installation se fait à l’aide de la fonctionnalité Packages du panneau de droite : cliquer sur Packages puis sur Install puis indiquer le nom du package comme dans le graphique ci-dessous.
Une fois installé, charger le package vcdExtra à l’aide de la commande library(vcdExtra).
Enfin on accède aux données en tapant
On peut alors visualiser le contenu
ainsi que son résumé :
pclass survived sex age sibsp
1st:323 died :809 female:466 Min. : 0.1667 Min. :0.0000
2nd:277 survived:500 male :843 1st Qu.:21.0000 1st Qu.:0.0000
3rd:709 Median :28.0000 Median :0.0000
Mean :29.8811 Mean :0.4989
3rd Qu.:39.0000 3rd Qu.:1.0000
Max. :80.0000 Max. :8.0000
NA's :263
parch
Min. :0.000
1st Qu.:0.000
Median :0.000
Mean :0.385
3rd Qu.:0.000
Max. :9.000
Pour obtenir une description de son contenu, il suffit de taper le nom du dataframe (Titanicp) dans l’onglet Help du panneau de droite (au milieu) :
Table de contingence et représentations
Rappel. Une table de contingence est produite par le croisement de deux variables catégorielles. Il s’agit d’un tableau où les lignes correspondent aux modalités d’une variable catégorielle et les colonnes aux modalités d’une autre variable catégorielle.
Prenons par exemple la table de contingence suivante :
| died | survived | |
|---|---|---|
| female | 127 | 339 |
| male | 682 | 161 |
Les lignes de cette table de contingence correspondent aux modalités de la variable sex alors que les colonnes correspondent aux modalités de la variable survived. Chaque case de la table de contingence est associée à un couple de modalités. La valeur qui y figure est le nombre d’individus observés prenant le couple de modalités qui lui est associé. Par exemple, on peut lire que 127 femmes n’ont pas survécu au naufrage du paquebot.
De façon générale, la table de contingence fournit les effectifs conjoints correspondants aux couples de modalités issus du croisement de 2 varaibles catégorielles.
Construction d’une table de contingence
La fonction table() permet de construire une table de contingence à partir d’un dataframe. L’exemple précédent est obtenu en exécutant la commande
En tapant
on affiche la table de contingence :
died survived
female 127 339
male 682 161Représentation graphique de type mosaïque
Une fois la table de contingence construite, R propose des outils graphiques pour la représenter. La fonction mosaicplot() permet de représenter une table de contingence sous forme de “mosaïque” :
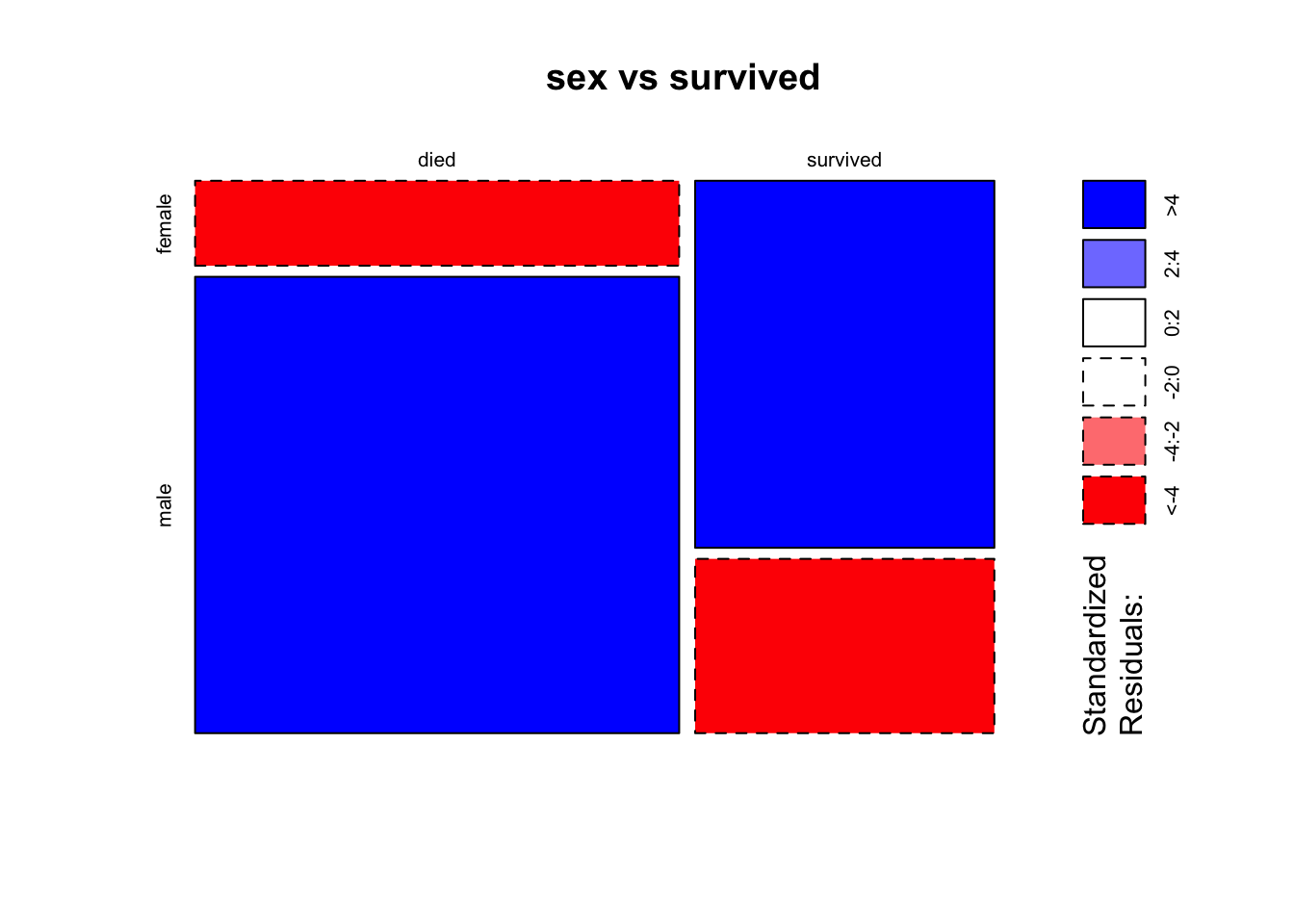
Pour chaque modalité en ligne (resp. en colonne), la hauteur (resp. largeur) des rectangles est proportionnelle à l’effectif marginal de la modalité considérée. L’option shade = TRUE ajoute un code couleur qui permet de savoir si un couple de modalités est en sur effectif (bleu foncé) ou en sous effectif (rouge) par rapport à une situation où les deux variables seraient indépendantes.
Commentaire. Les seules couleurs présentes étant le bleu foncé et le rouge :
- le taux de mortalité chez les hommes est bien plus important que celui des femmes
- on peut dire qu’il existe un lien entre les 2 variables sex et survived.
Remarque. Cette représentation de type mosaïque est une façon de représenter graphiquement la relation entre 2 variables catégorielles.
Exercice 4.6 Représenter la relation entre la variable pclass et survived puis commenter.
V de Cramér
Rappel. Le V de Cramér (que l’on note \(V_C\)) est un indicateur mesurant l’intensité de la liaison qui peut exister entre 2 variables qualitatives. Son calcul est basé sur le khi-deux d’indépendance (\(\chi^2\)) : \[ V_C = \sqrt{\frac{\chi^2}{n \times \left[min(L,C) - 1\right]}} \] où \(n\) = effectif total, \(L\) = nombre de lignes de la table de contingence et \(C\) = nombre de colonnes de la table de contingence. Le V de Cramér mesure l’écart à l’indépendance en fournissant une valeur comprise entre 0 et 1 :
- \(0 \leq V_C \leq 0.3\) : intensité de liaison très faible
- \(0.3 < V_C \leq 0.5\) : intensité de liaison faible
- \(0.5 < V_C \leq 0.7\) : intensité de liaison moyenne
- \(0.7 < V_C \leq 1\) : intensité de liaison forte
La valeur du khi-deux d’indépendance (\(\chi^2\)) s’obtient à l’aide de la fonction R chisq.test() :
À partir du \(\chi^2\), il est facile de construire une fonction que l’on nommera cramer.v() dédiée au calcul du V de Cramér (\(V_C\)) en exécutant les lignes suivantes
cramer.v = function(TABLECONT){
khi2 = chisq.test(TABLECONT)$statistic
ntot = sum(TABLECONT)
L = nrow(TABLECONT)
C = ncol(TABLECONT)
V_C = sqrt(khi2 / (ntot * (min(L, C) - 1)))
return(V_C)
}Pour calculer \(V_C\) sur la table de contingence CONT_SEX_SURV, il suffit de taper
pour obtenir le V de Cramér mesurant l’intensité du lien entre les variables sex et survived :
X-squared
0.5270512 On a donc \(V_C(\)sex, survided\()\simeq 0.53\)
Conclusion : l’intensité du lien entre les variables sex et survived est moyenne.
Remarque. Ce calcul confirme le commentaire réalisé à partir de la représentation de type mosaïque
Exercice 4.7 Que pouvez-vous dire sur l’intensité du lien entre la classe tarifaire et le fait d’être rescapé du naufrage?
Distribution conditionnelle
Lorsqu’on observe simultanément deux variables catégorielles V1 et V2 sur un même échantillon, la table de contingence fournit les effectifs conjoints c’est-à-dire la distribution conjointe des deux variables catégorielles V1 et V2. À partir de la distribution conjointe, on peut construire deux distributions conditionnelles : la distribution de V1 conditionnellement à V2 et la distribution de V2 conditionnellement à V1.
Exemple des naufragés du Titanic
Distribution de la variable sex conditionnellement à la variable survived
La distribution de la variable sex conditionnellement à la variable survived est obtenue à l’aide de la fonction prop.table(). L’argument principal est une table de contingence (ici la table CONT_SEX_SURV calculée précédemment). L’option margin = 2 indique qu’on calcule la distribution de la variable dont les modalités sont en ligne dans la table de contingence (ici female et male) pour chaque modalité en colonne (died et survived). La commande suivante
permet d’afficher la distribution de la variable sex conditionnellement à la variable survived :
died survived
female 0.1569839 0.6780000
male 0.8430161 0.3220000La somme de chaque colonne est égale à 1 ; pour chaque modalité en colonne (died et survived), la fréquence de la modalité femme (resp. homme) est calculée.
On peut ensuite représenter graphiquement cette distribution conditionnelle à l’aide de la fonction barplot() :
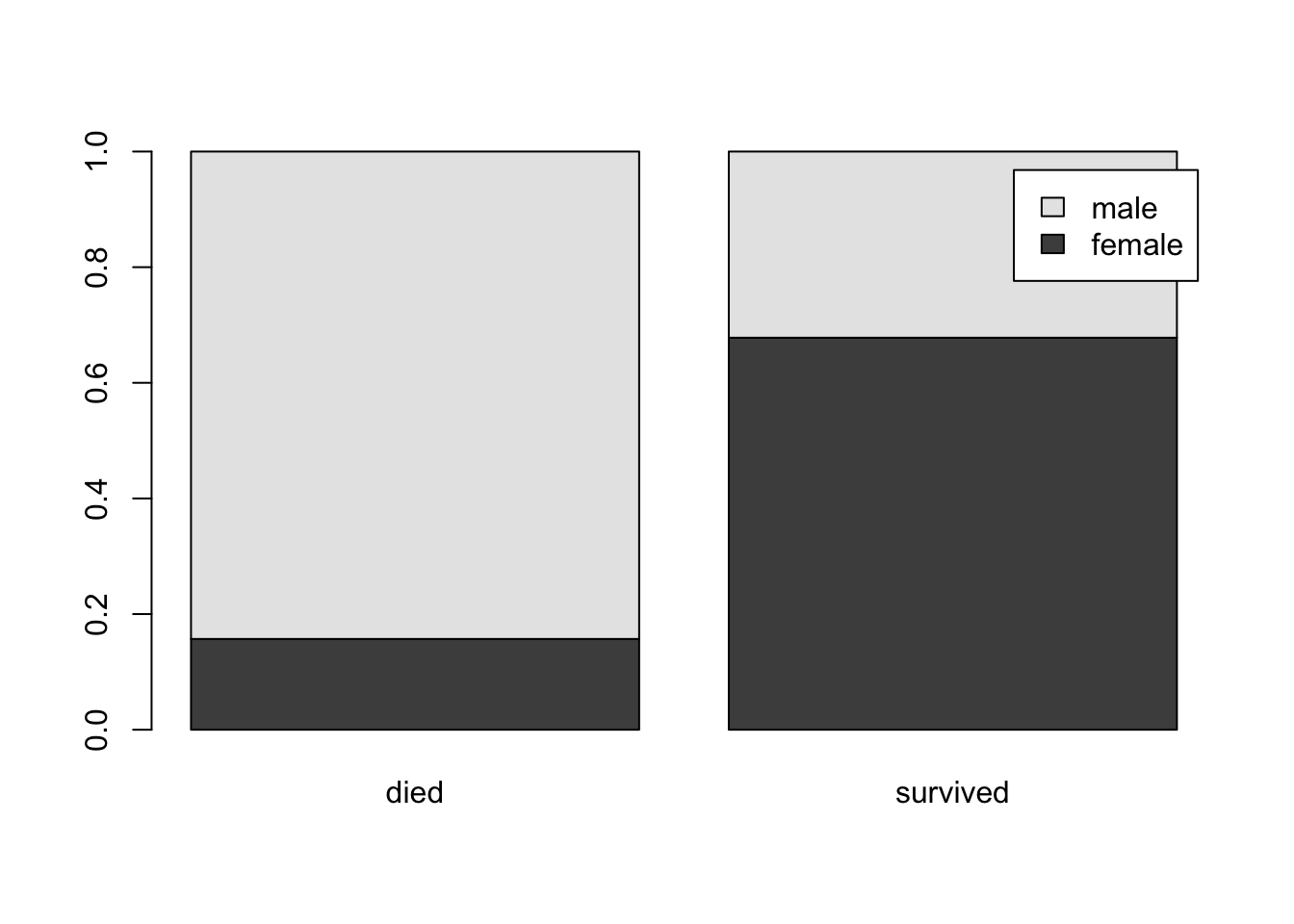
Commentaire. Ce graphique indique la proportion de femmes et d’hommes en fonction de leur devenir durant le naufrage. On remarque un changement très important de la proportion de femmes lorsqu’on passe de la modalité died à la modalité survived. Cela indique l’existence probable d’un lien assez fort entre le sexe des individus et leur devenir pendant le naufrage.
Distribution de la variable survived conditionnellement à la variable sex
La distribution de la variable survived conditionnellement à la variable sex est obtenue avec l’option margin = 1. Cela indique qu’on calcule la distribution de la variable dont les modalités sont en colonne dans la table de contingence (ici died et survived) pour chaque modalité en ligne (female et male). La commande suivante
permet d’afficher la distribution de la variable survived conditionnellement à la variable sex :
died survived
female 0.2725322 0.7274678
male 0.8090154 0.1909846Cette fois, c’est la somme de chaque ligne qui est égale à 1 ; pour chaque modalité en ligne (female et male), la fréquence de la modalité died (resp. survived) est calculée.
On peut ensuite représenter graphiquement cette distribution conditionnelle à l’aide de la fonction barplot() :
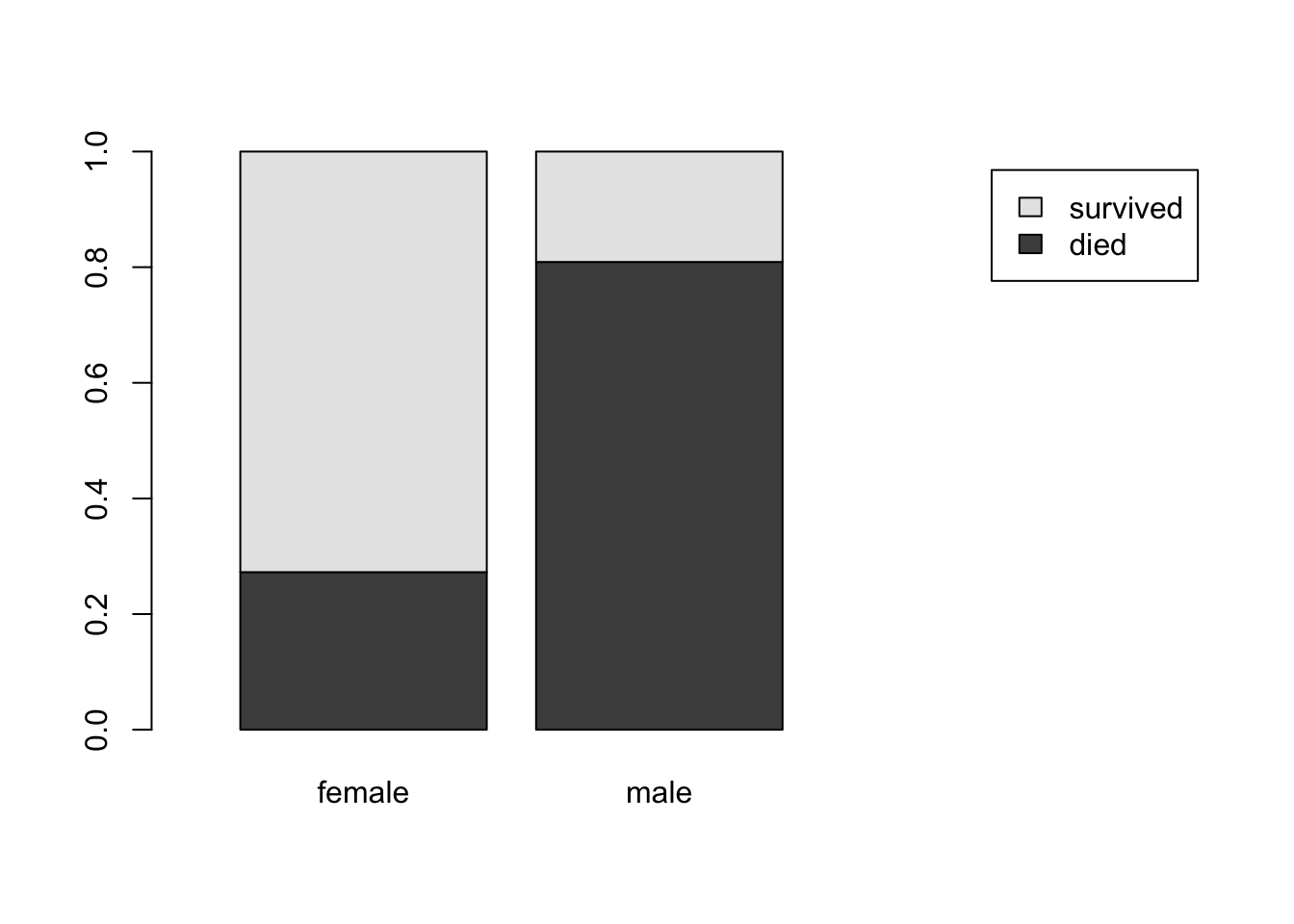
Remarque 1 : il est nécessaire d’inverser les lignes et colonnes donnant la distribution conditionnelle à l’aide de la fonction t() pour obtenir le bon graphique.
Remarque 2 : l’option xlim = c(0,4) permet de réduire la longueur de l’axe horizontal afin d’éviter un chevauchement avec la légende (vous pouvez remplacer 4 par d’autres valeurs pour observer l’effet de cette option).
Commentaire. Ce graphique indique la proportion de survivants en fonction du sexe. On remarque encore un changement très important de la proportion de survivants lorsqu’on passe de la modalité female à la modalité male. Cela indique à nouveau l’existence probable d’un lien assez fort entre le sexe des individus et leur devenir pendant le naufrage.
Exercice 4.8 Représenter les deux distributions conditionnelles que l’on peut calculer à partir de la classe tarifaire du billet (1st, 2nd et 3rd) et l’issue du naufrage (died ou survived). Commenter les graphiques.
4.3 Une variable catégorielle et une variable quantitative
Cette section s’intéresse au lien qui peut exister entre une variable quantitative et une variable catégorielle.
Données économiques
Pour fixer les idées, reprenons les données économiques utilisées à la section 4.1 Deux variables quantitatives. Pour rappel, ces données concernent les organismes de micro-financement (OMF). Les données sont disponibles en ligne à l’adresse
https://www.math.univ-toulouse.fr/~ferraty/DATA/micro_finance.csv.
Une fois le fichier téléchargé, importer ces données dans votre session R en utilisant la fonctionnalité “Import Dataset” de RStudio (sans oublier de cocher l’option “stringsAsFactors”). Vous créerez un objet R appelé MICFIN qui contiendra l’ensemble de ces données puis procéder à la transformation logarithmique des variables quantitatives :
# transformation logarithmique des variables quantitatives
MICFINLOG = cbind(MICFIN[, 1:8], log(MICFIN[, 9:15]))
# affectation de labels aux variables transformées
colnames(MICFINLOG)[9:15] = c("logAssets", "logPersonnel.expense.to.assets", "logNb.active.borrowers", "logNb.depositors", "logPersonnel.expense", "logPersonnel", "logEfficience")Une fois les données chargées sous la session R courante, peut-on savoir par exemple s’il existe un lien entre la variable quantitative logAssets (logarithme des actifs de l’OMF) et la variable catégorielle Scale (taille de l’OMF –> Large/Medium/Small)?
Description graphique d’un lien
Une façon de décrire cette liaison est de représenter la distribution de logAssets selon les 3 modalités de Scale (Large / Medium / Small).
Boîtes-à-moustaches (boxplots) selon les modalités d’une variable catégorielle
Exécuter la commande suivante :
La formule logAssets ~ Scale indique que l’on souhaite représenter la distribution de logAssets en fonction des modalités de Scale. L’option data = MICFINLOG indique le nom du dataframe qui contient les variables logAssets et Scale. Cette commande produit le graphique suivant :
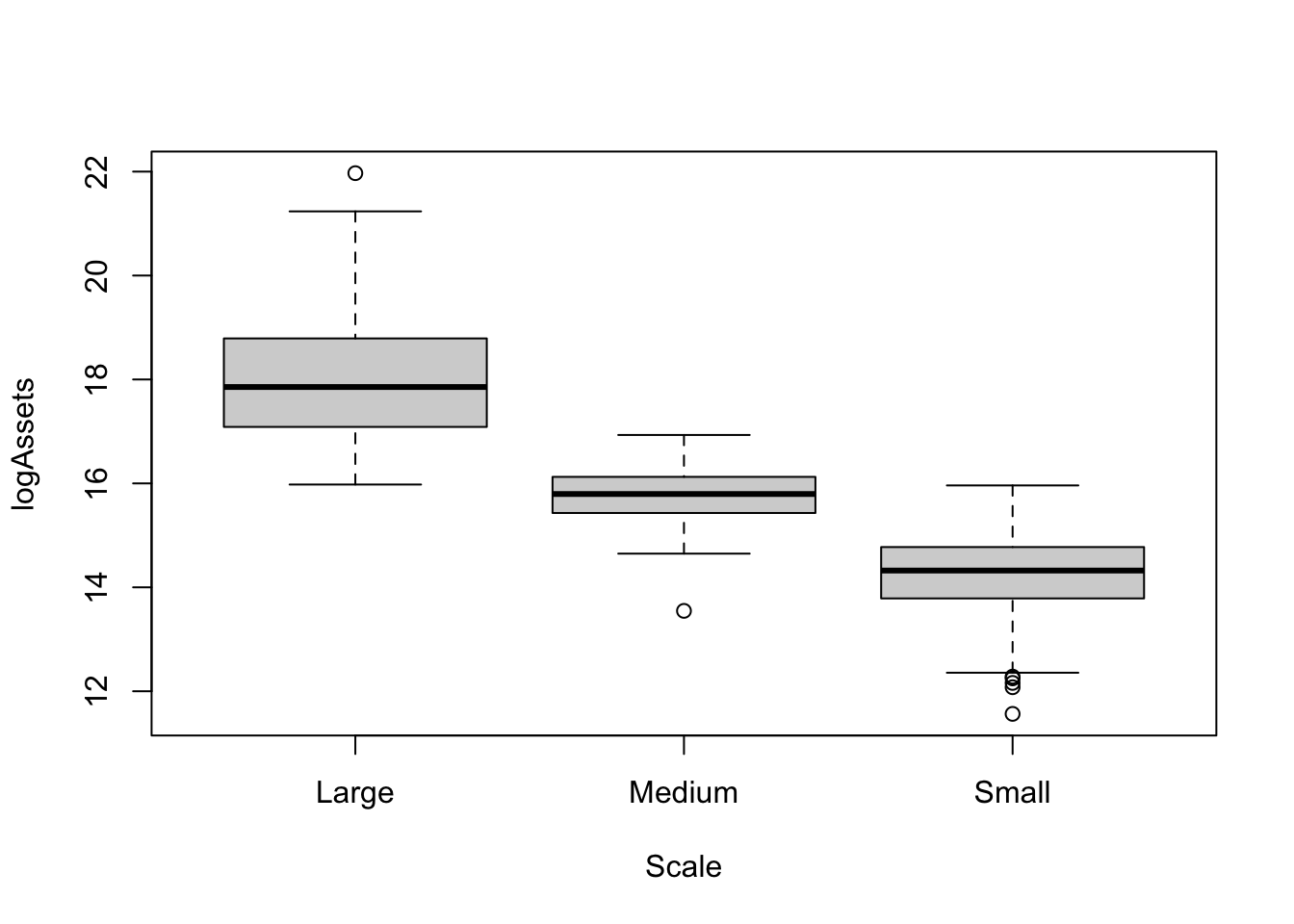
Pour chacune des 3 sous-populations d’OMF (Large / Medium / Small), on représente la distribution de logAssets à l’aide d’une boîte-à-moustaches.
Commentaires. On remarque des différences marquées dans la distribution de la variable logAssets selon la taille de l’OMF. Les actifs les plus élevés sont observés pour les OMF de grandes tailles. Les actifs pour les OMF de tailles moyennes diminuent nettement. Enfin, une baisse significative des actifs est encore observée entre les OMF de tailles moyennes et celles de plus petites tailles. D’un point de vue de la variabilité, on remarque aussi des différences selon la taille de l’OMF. Les actifs des OMF de tailles moyennes sont plus concentrés (i.e plus petite variance) que ceux des OMF de petites tailles. Quant aux actifs des OMF de grandes tailles, ils possèdent la plus grande variance.
Conclusion. La distribution des actifs des OMF est fortement modifiée lorsqu’on passe d’une taille à une autre. Cela indique qu’il existe vraisemblablement un lien entre les actifs des OMF et leurs tailles.
Remarque : on peut rajouter de la couleur pour différencier les boxplots à l’aide de l’option col = de la fonction boxplot
Exercice 4.9 1. Représenter à l’aide de boîtes-à-moustaches la relation entre le logarithme des actifs des OMF et leur mode de régulation (variable Regulated possédant les 2 modalités “no” et “yes”). 2. À votre avis, le lien entre les variables logAssets et Regulated est-il plus fort ou plus faible que celui entre logAssets et Scale?
Histogrammes selon les modalités d’une variable catégorielle
La fonction histogram du package lattice permet de représenter des histogrammes selon les modalités d’une variable catégorielle. Une fois la librairie lattice chargée grâce à la commande,
la ligne
indique qu’il faut représenter l’histogramme de la variable logAssets pour chaque sous-population d’OMF définie par la variable Scale (Large/Medium/Small), les variables étant contenues dans le dataframe MICFINLOG.
Cette commande produit simultanément les 3 histogrammes suivants :
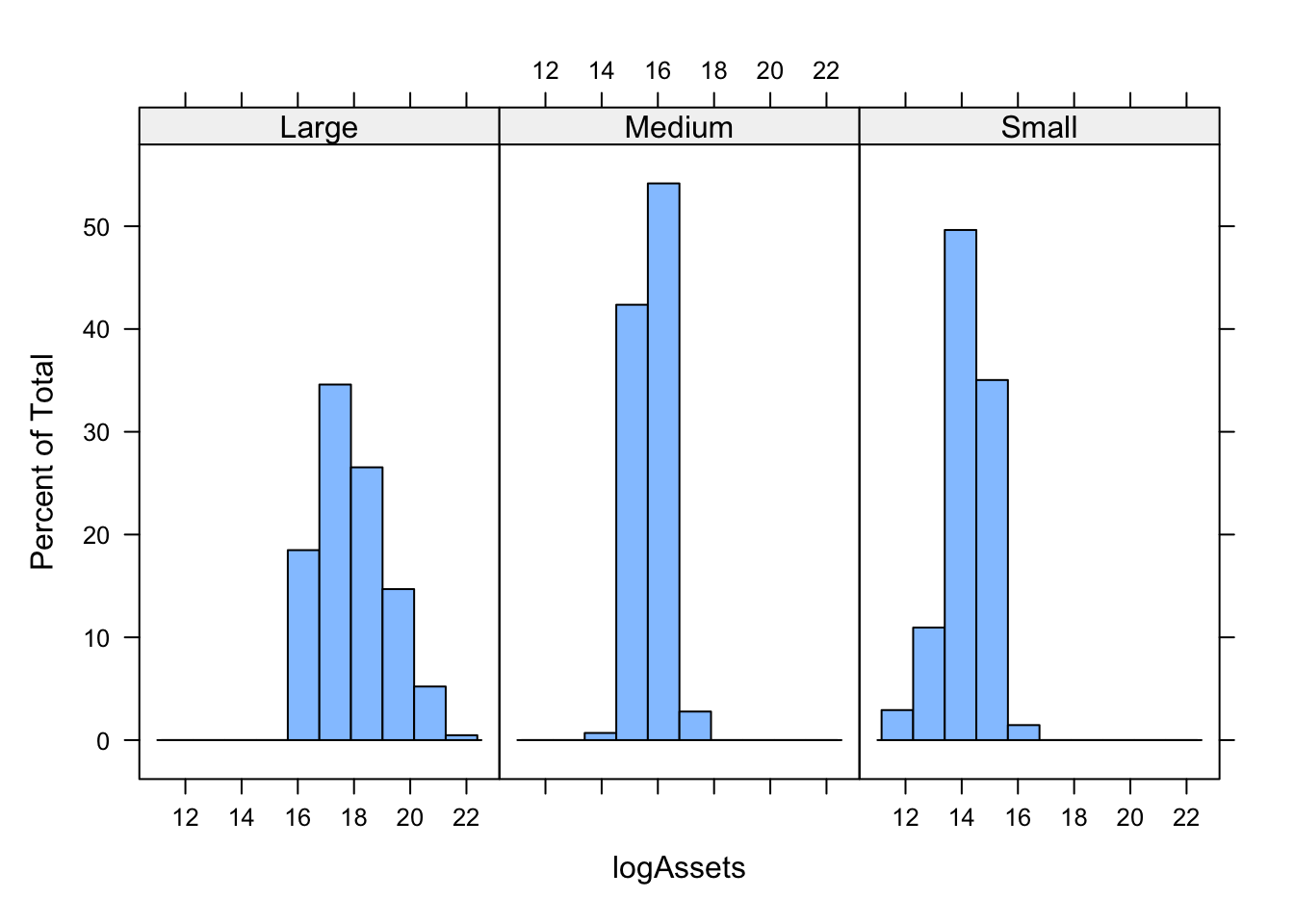
Pour chaque sous-population d’OMF définie à partir de leur taille (Large/Medium/Small), on obtient un histogramme décrivant la distribution du logarithme des actifs (logAssets).
Commentaires. On remarque le même comportement observé pour les boxplots. Des différences marquées dans la distribution de la variable logAssets selon la taille de l’OMF apparaissent. Les actifs des OMF de grandes tailles se répartissent sur les valeurs les plus élevés (entre 16 et 20 avec un pic autour de 18). Les actifs pour les OMF de tailles moyennes se concentrent très fortement entre 14 et 17. Enfin, les OMF de petites tailles se répartissent essentiellement entre 13 et 16.
La même conclusion que celle faite précédemment s’impose : la distribution des actifs des OMF est fortement modifiée lorsqu’on passe d’une taille à une autre. Cela indique qu’il existe vraisemblablement un lien entre les actifs des OMF et leurs tailles.
Exercice 4.10 1. Recommencer en remplaçant la variable catégorielle Scale par Regulated 2. Commenter en comparant ce nouveau graphique avec le précédent.
Exercice 4.11 À votre avis, vous qualifieriez le lien entre le nombre d’emprunteurs et le mode de régulation des OMF de fort ou faible?
Mesure de l’intensité de liaison entre une variable quantitative et une variable catégorielle : le rapport de corrélation
On a vu comment décrire graphiquement la relation qu’il peut exister entre une variable quantitative et une variable catégorielle. Nous allons voir maintenant comment ce type de liaison peut être mesuré grâce à un nouvel indicateur numérique : le rapport de corrélation.
\(\color{blue}X\) var. quantitative \(\longrightarrow\) \(x_1, \, x_2, \ldots, x_n\)
\(\color{red}Q\) var. catégorielle avec \(K\) modalités \(\longrightarrow\) \(K\) groupes d’individus :
- \(n_k\) = effectif groupe n\(^o k\)
- \(\overline{x}^k\) = moyenne de \(\color{blue}X\) pour groupe n\(^o k\)
Le rapport de corrélation, noté \(\eta({\color{blue}X}, {\color{red}Q})\), est défini par : \[\eta({\color{blue}X}, {\color{red}Q}) \, =\, \sqrt{\frac{\sum_{k=1}^K n_k \left(\overline{x}^k - \overline{x}\right)^2}{\sum_{i=1}^n \left(x_i - \overline{x} \right)^2}}\]
\(\boldsymbol{0 \leq \eta( {\color{blue}X}, {\color{red}Q} ) \leq 1}\)
\(\boldsymbol{\eta( {\color{blue}X}, {\color{red}Q} ) = 0}\)
- \(\overline{x}^1 = \overline{x}^2 = \cdots = \overline{x}^K = \overline{x}\)
- pas d’effet groupe sur les moyennes
- liaison nulle entre \(\color{blue}X\) et \(\color{red}Q\)
\(\boldsymbol{\eta( {\color{blue}X}, {\color{red}Q} )} = 1\)
- les \(x_i\) sont identiques à l’intérieur de chaque groupe
- effet groupe maximal sur les \(x_i\)
- liaison maximale entre \(\color{blue}X\) et \(\color{red}Q\)
Pour fixer les idées, reprenons l’exemple des données économiques sur les OMF (organismes de micro-financement) en se focalisant sur la variable logAssets en fonction des modalités de la variable Scale (Large/Medium/Small). Le graphique suivant (appelé stripchart), représente les valeurs observées pour la variable logAssets selon les 3 catégories d’OMF définies par la taille :
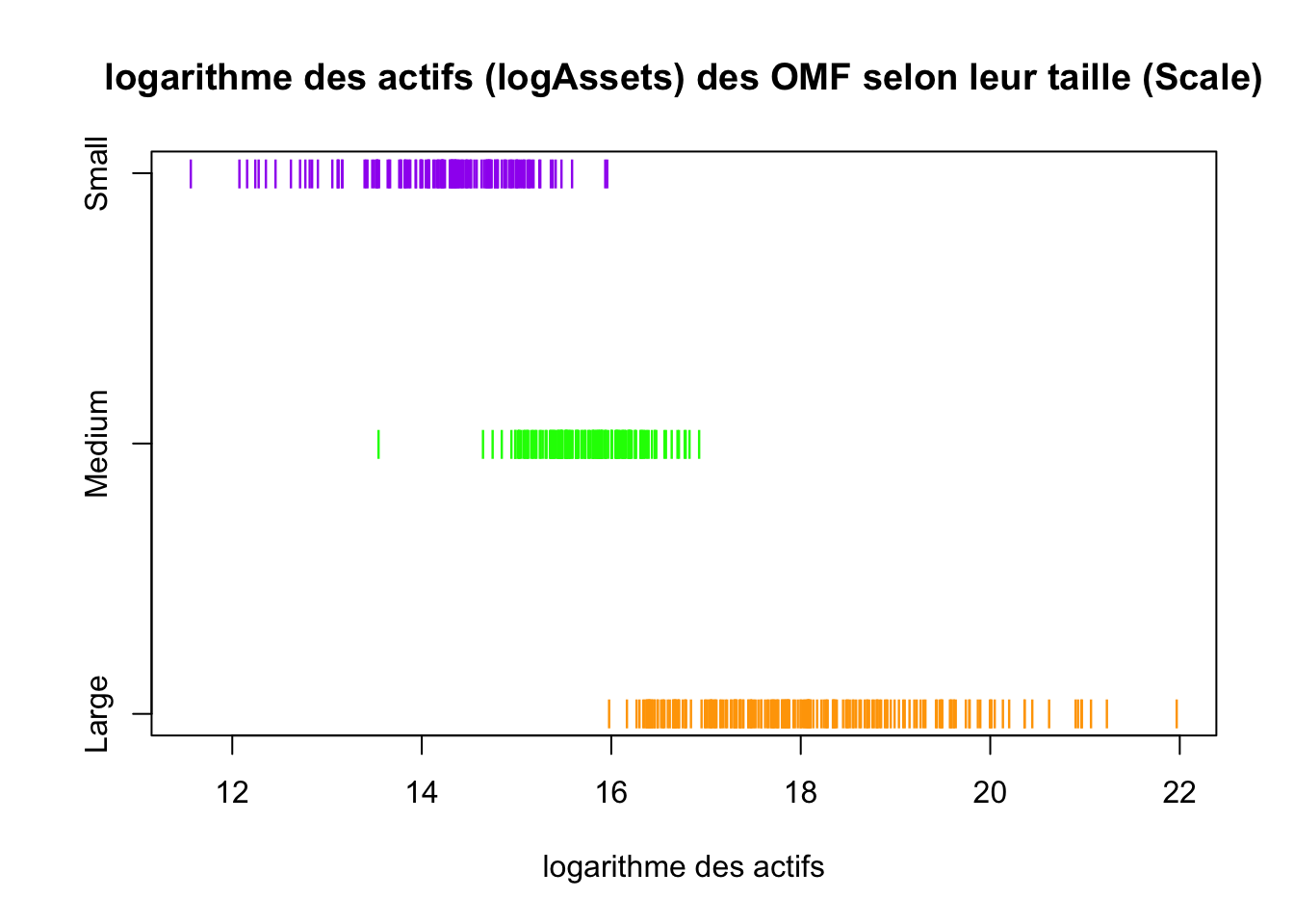
137 OMF sont de petite taille (groupe violet), 144 OMF considérées comme étant de taille moyenne (groupe vert) et 211 OMF sont de grande taille (groupe orange). Dans ce cas :
- \(n_1 = 137\) et \(\overline{x}^1 \simeq 14.20\) (groupe violet)
- \(n_2 = 144\) et \(\overline{x}^2 \simeq 15.76\) (groupe vert)
- \(n_3 = 211\) et \(\overline{x}^3 \simeq 18.02\) (groupe orange)
- moyenne globale \(\overline{x} \simeq 16.30\) (\(n = 492\))
Calculons \(\eta(logAssets,\, Scale)\), le rapport de corrélation entre le logarithme des actifs (logAssets) et la taille des OMF (variable catégorielle possédant les 3 modalités Large/Medium/Small). Le rapport de corrélation est un sous-produit de la fonction lm()
Remarque : lm est l’abréviation de linear model qui regroupe un ensemble d’outils d’analyse statistique assez pointus. Ces techniques sont généralement abordées en fin de licence ou bien en Master.
L’exécution des commandes suivantes
fournit le rapport de corrélation \(\eta(logAssets,\, Scale)\) :
[1] 0.8613292\(\eta(logAssets,\, Scale)\) est élevé (proche de 1) ce qui indique une intensité de liaison forte entre la variable quantitative logAssets et la variable catégorielle Scale.
Exercice 4.12
- Données économiques : caluler \(\eta(logAssets,\, Regulated)\) puis comparer avec \(\eta(logAssets,\, Scale)\)
- Données sur le naufrage du Titanic : caluler le rapport de corrélation entre la variable age et la variable survived puis recommencer avec la variable age et la variable sex. Que pouvez-vous en déduire?