Chapter 3 Statistique univariée
3.1 Jeux de données disponibles dans le package questionr
On utilise ici 2 jeux de données disponibles dans le package questionr. Avant d’accéder à ces données, il faut charger le package questionr à l’aide de la commande
Remarque : si la commande précédente ne fonctionne pas sur votre ordinateur personnel (déjà installé sur les ordinateurs de la salle machine), il est possible que le package questionr ne soit pas installé. Dans ce cas, il faudra l’importer à l’aide de la fonctionnalité Packages>Install (panneau de droite) puis le charger dans votre session R à l’aide de la commande library(questionr)
Une fois le package questionr chargé sous R, on accède à différents jeux de données notamment hdv2003 (Histoire de Vie en 2003) et rp2018 (recensement population 2018 pour chaque commune).
Données Histoire de Vie en 2003 (source INSEE)
La fonction data() permet d’activer ces jeux de données (c’est-à-dire de les rendre utilisables) en précisant le nom du package qui les contient :
Une fois le jeu de données activé, on peut le manipuler avec les fonction R.
Exercice 3.1 Répondez aux questions suivantes :
Visualiser le tableau de données hdv2003
Afficher le résumé du tableau de données hdv2003
Décrire la nature des variables contenues dans hdv2003
Données recensement 2018 (source INSEE)
Le package questionr contient un autre tableau de données appelé rp2018. Ce jeu de données décrit 5417 villes (individus) à l’aide de 62 caractéristiques (variables) parmi lesquelles : % d’agriculteurs dans la population active (agric), % d’indépendants (indep), part des cadres (cadres), % d’ouvriers, % de propriétaires (proprio), % de logements HLM (hlm), % de locataires (locataire), % de maisons (maison).
Exercice 3.2 Répondez aux questions suivantes :
Activer le tableau de données rp2018 à l’aide de la fonction data() puis visualiser le tableau de données rp2018
Afficher le résumé du tableau de données rp2018
Décrire la nature des variables contenues dans rp2018
3.2 Variables quantitatives
Indicateurs numériques (moyenne, médiane, quartiles, écart-type/variance)
Usage standard
# mean --> calcul de la moyenne
mean(hdv2003$heures.tv)
# prise en compte des valeurs manquantes (NA) avec l'option 'na.rm = TRUE'
mean(hdv2003$heures.tv, na.rm = TRUE)
# sd --> calcul de l'écart-type
sd(hdv2003$heures.tv, na.rm = TRUE)
# v ar--> calcul de la variance
var(hdv2003$heures.tv, na.rm = TRUE)
# min --> plus petite valeur
min(hdv2003$heures.tv, na.rm = TRUE)
# max --> plus grande valeurs
max(hdv2003$heures.tv, na.rm = TRUE)
# range fournit un vecteur possédant contenant le minimum et le maximum
range(hdv2003$heures.tv, na.rm = TRUE)
# median --> calcul de la médiane
median(hdv2003$heures.tv, na.rm = TRUE)
# résumé de la variable 'heures.tv'
summary(hdv2003$heures.tv)Indicateurs selon les modalités d’une variable catégorielle
La fonction by() permet de calculer ce type d’indicateurs
# moyenne d'age selon que la personne écoute ou non du hard.rock pendant son temps de loisir
by(hdv2003$age, hdv2003$nivetud, mean)Remarque : le même procédé s’applique aux fonctions sd(), var(), median(),… (l’option na.rm = T peut être utilisée en présence de données manquantes NA)
Exercice 3.3 Répondez aux questions suivantes :
Calculer la moyenne d’âge selon les groupes formés par la variable hard.rock. Même question pour les écart-types. À votre avis, existe-t-il un lien entre la variable age et la variable catégorielle hard.rock
Trouver une autre variable catégorielle pour laquelle il existe un lien avec la variable age
Trouver une autre variable catégorielle pour laquelle il vous semble qu’il n’y a pas de lien avec la variable age
Mêmes questions en prenant comme variable quantitative heures.tv
Représentations graphiques
Boîtes-à-moustaches (boxplot)
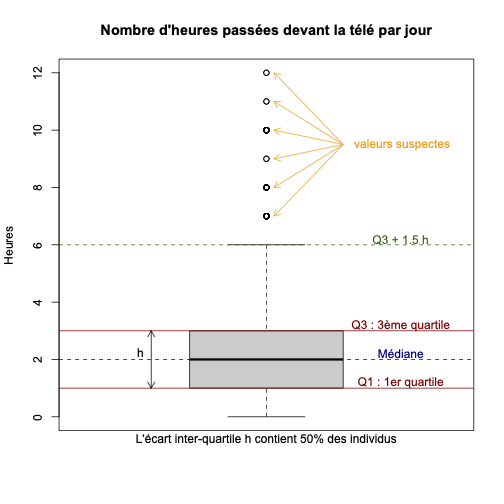
Boîtes-à-moustaches? Pour rappel, une boîte-à-moustaches est une représentation simplifiée de la distribution d’une variable quantitative (c’est-à-dire la façon dont les valeurs observées se répartissent). Exemple avec la variable heures.tv issue de l’enquête Histoire de Vie en 2003 :
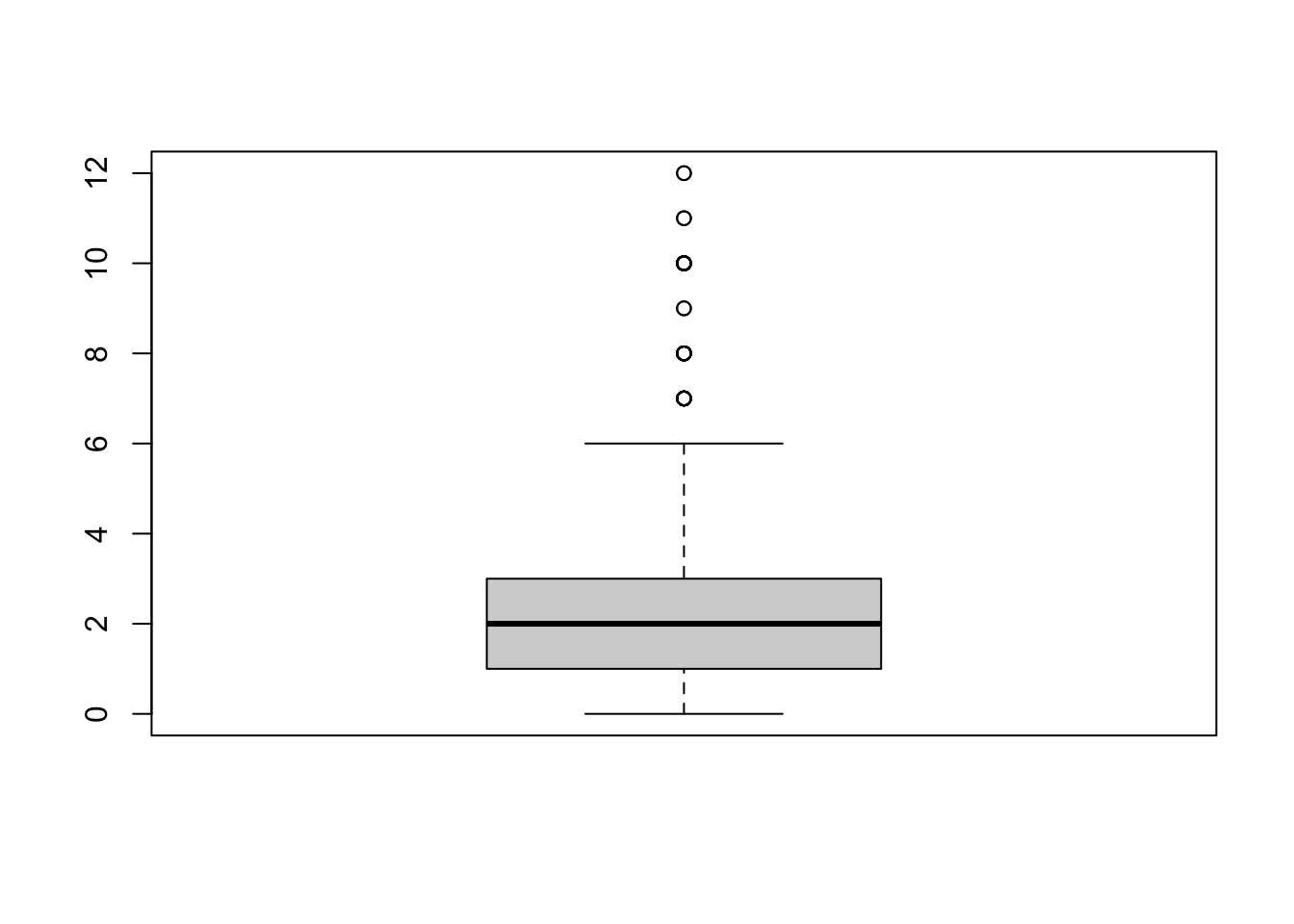
La fonction boxplot() de R permet de représenter des boîtes-à-moustaches. Pour produire cette boîte-à-moustaches, assurez-vous que les données Histoire de Vie 2003 sont présentes dans votre session R (si ce n’est pas le cas, vous devrez les charger à nouveau) puis exécuter le script suivant :
On peut rendre ce graphique plus lisible en rajoutant des informations (titre, labels,…) :
# usage avec personnalisation des options
boxplot(hdv2003$heures.tv, main = "Nombre d'heures passées devant la télé par jour", ylab = "nb heures", col = "purple")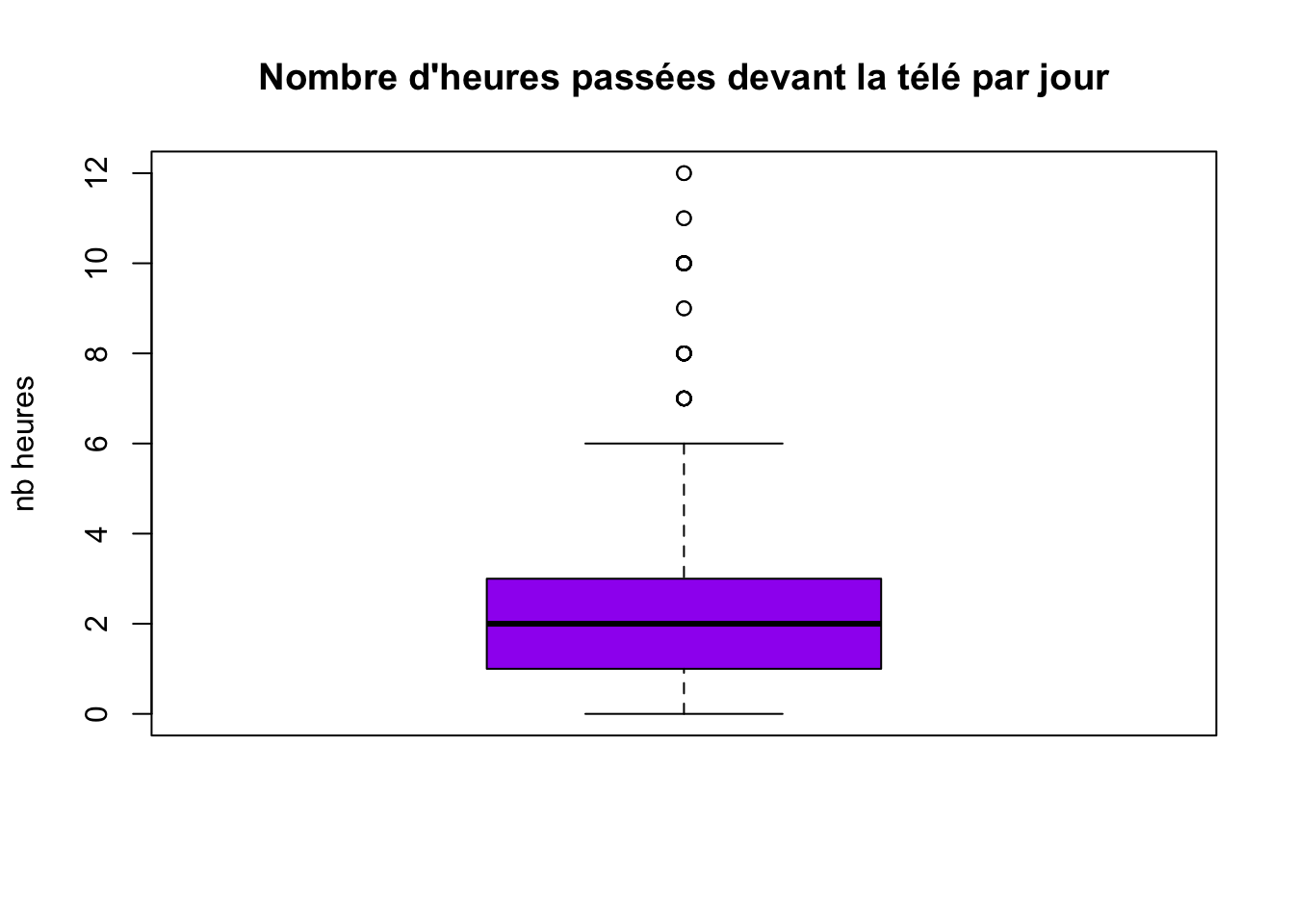
Grâce aux listes (rappel : la fonction R list permet de créer une liste d’objets), on peut représenter simultanément plusieurs boîtes-à-moustaches (ici on se contente de 2 boxplots) :
boxplot(list(heures.tv = hdv2003$heures.tv, nb_freres_soeurs = hdv2003$freres.soeurs), main = "Boîtes-à-moustaches", col = c("orange", "green"))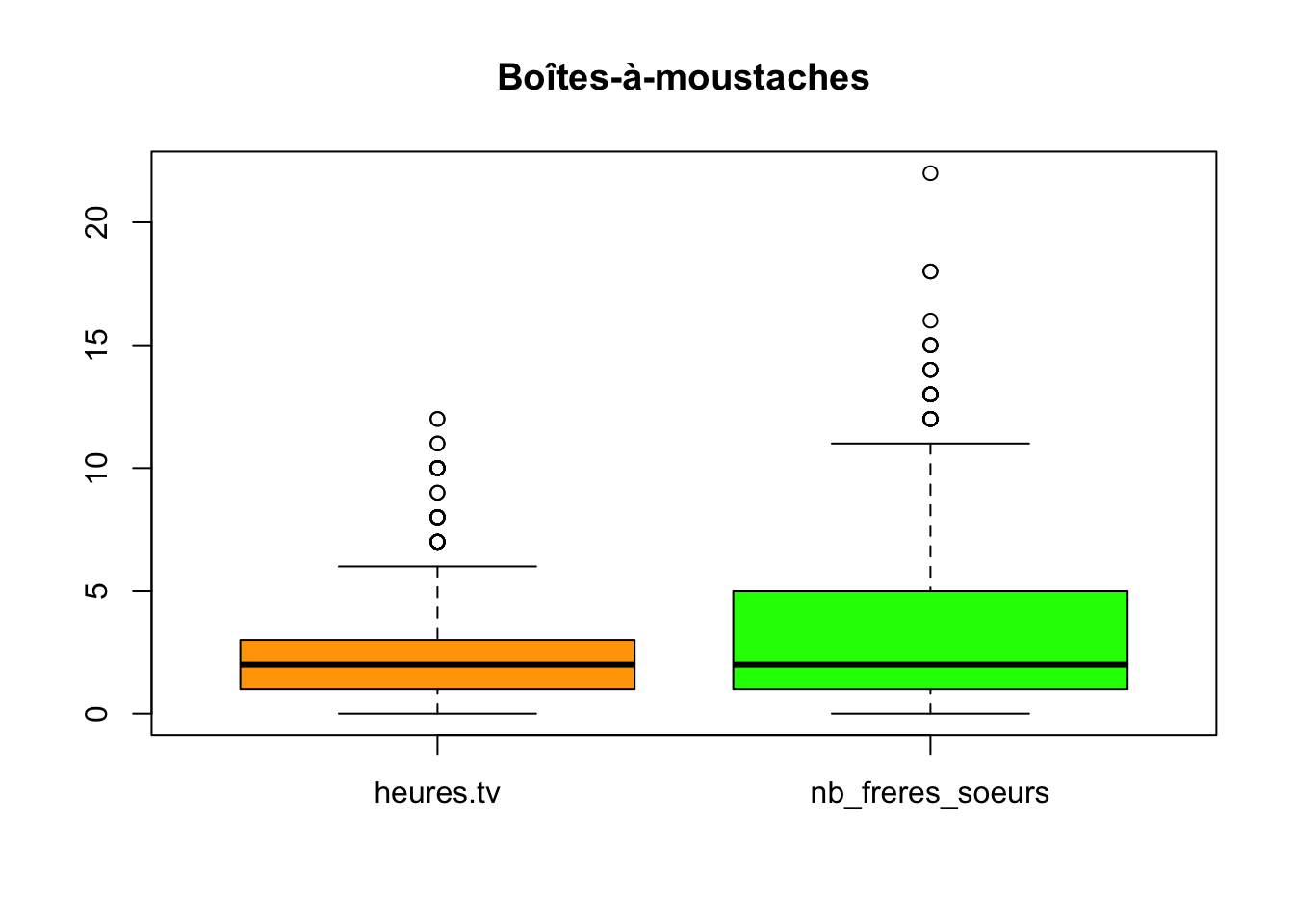
Remarque : toujours identifier clairement les objets que l’on représente (ici, importance des noms affectés aux boîtes-à-moustaches lors de la création de la liste)
Exercice 3.4 Répondez aux questions suivantes :
Assurez-vous que les données contenues dans rp2018 soient présentes dans votre session R (si ce n’est pas le cas, vous devez les charger)
Réaliser le graphique ci-après
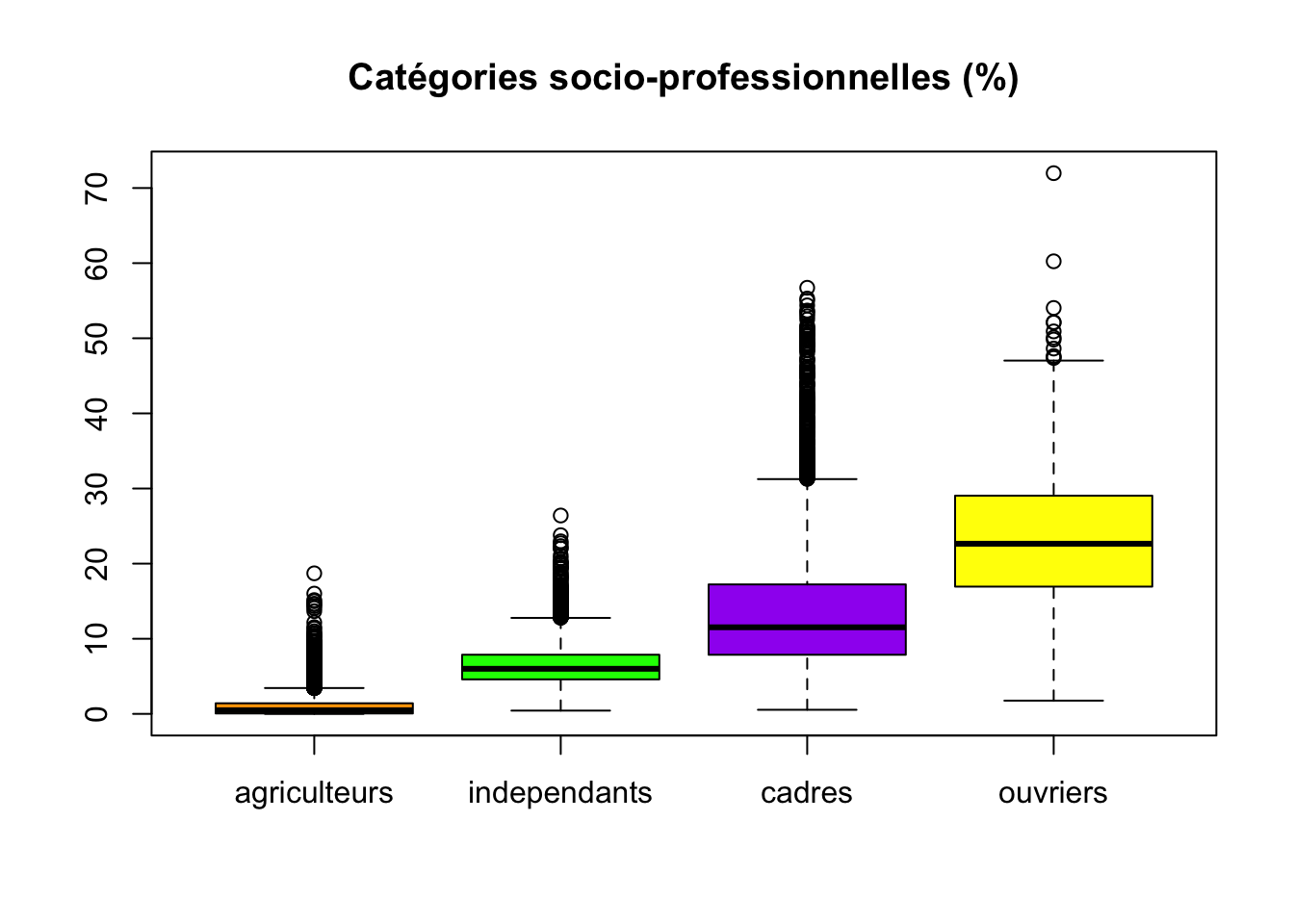
- Quelle catégorie socio-professionnelle est la plus importante? Quelle catégorie socio-professionnelle possède la distribution de plus petite variabilité? de plus grande variabilité
Exercice 3.5 Répondez aux questions suivantes :
Chargez les données de températures disponibles à l’adresse https://www.math.univ-toulouse.fr/~ferraty/DATA/acp-temperatures-villes-francaises.txt dans votre session R puis visualiser ce tableau de données
Réaliser le graphique ci-après
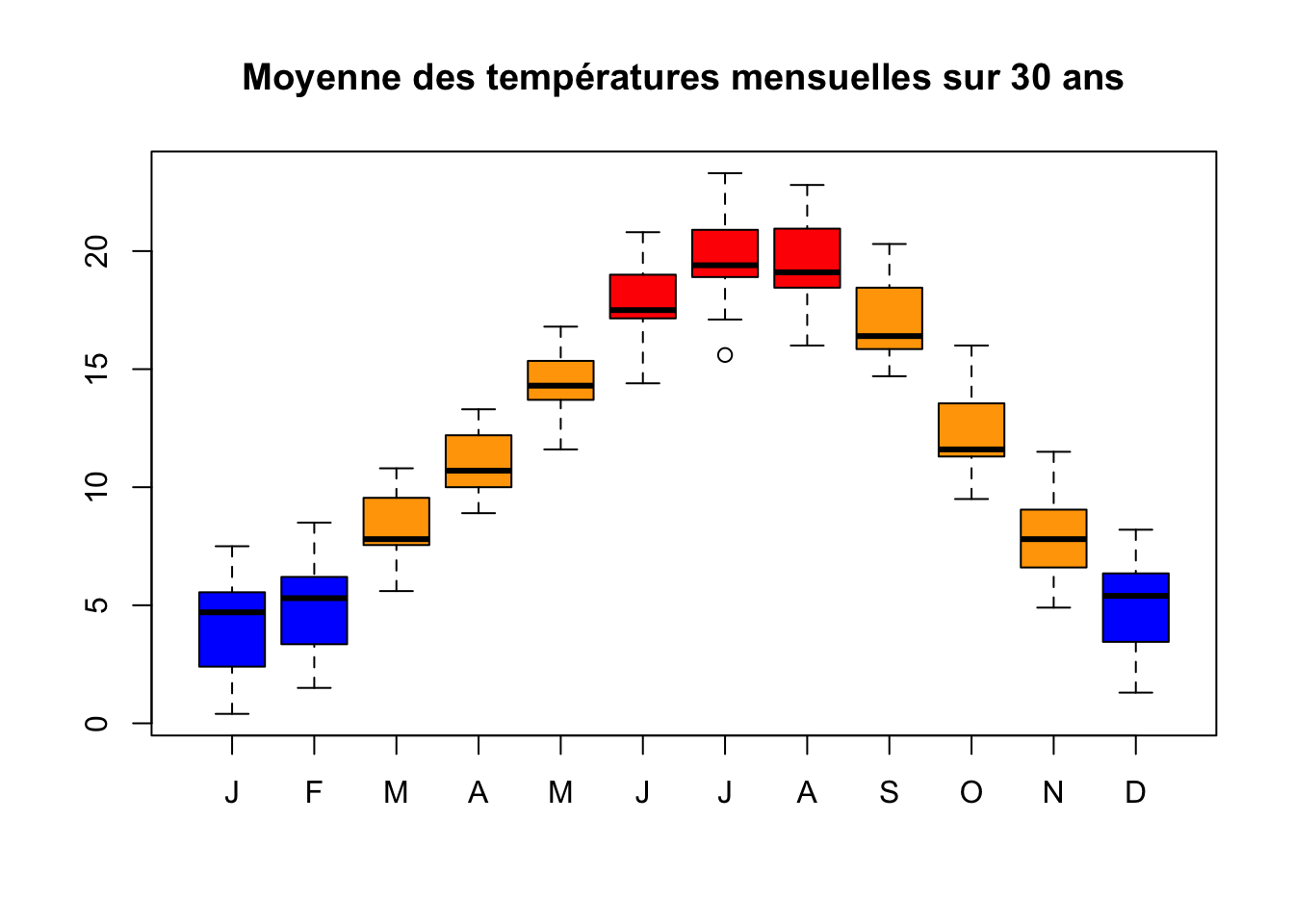
Commentez ce graphique ; pour quel mois la distribution des températures vous paraît-elle la plus symétrique?
Diagramme en bâtons
Rappel : un diagramme en bâtons représente la distribution des observations d’une variable quantitative discrète. L’axe horizontal indique chaque valeur observée ; l’axe vertical représente l’effectif associé à chacune des valeurs observées. Pour chaque valeur de la variable, on trace un “bâton” dont la hauteur correspond à son effectif.
Revenons à l’enquête Hstoire de vie 2003 et assurez-vous que l’objet R qui contient ces données (objet hdv2003 du package questionr) est bien reconnu dans votre session courante. Si ce n’est pas le cas, recharger ces données à l’aide des commandes
Une fois le dataframe hdv2003 disponible, on s’intéresse à la variable “nombre de frères et soeurs”. Pour pouvoir réaliser un diagramme en bâtons de cette variable, il est nécessaire de connaître les effectifs pour chaque modalité distincte. Ces effectifs sont déterminés automatiquement en utilisant la fonction table() de R. À l’aide de la commande suivante
les effectifs pour chaque modalité de la variable “nombre de frères et soeurs” sont affichés :
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 18 22
167 407 427 284 210 151 99 94 52 37 21 21 8 10 4 4 1 2 1 Une fois qu’on sait calculer les effectifs, on peut les représenter en fonction des modalités à l’aide de la fonction plot() de R :
plot(table(hdv2003$freres.soeurs), main = "Nb de frères, soeurs, demi-frères et demi-soeurs", ylab = "Effectifs")
On peut améliorer ce graphique en traçant des bâtons plus épais avec l’option lwd
plot(table(hdv2003$freres.soeurs), main = "Nb de frères, soeurs, demi-frères et demi-soeurs", ylab = "Effectifs", lwd = 5)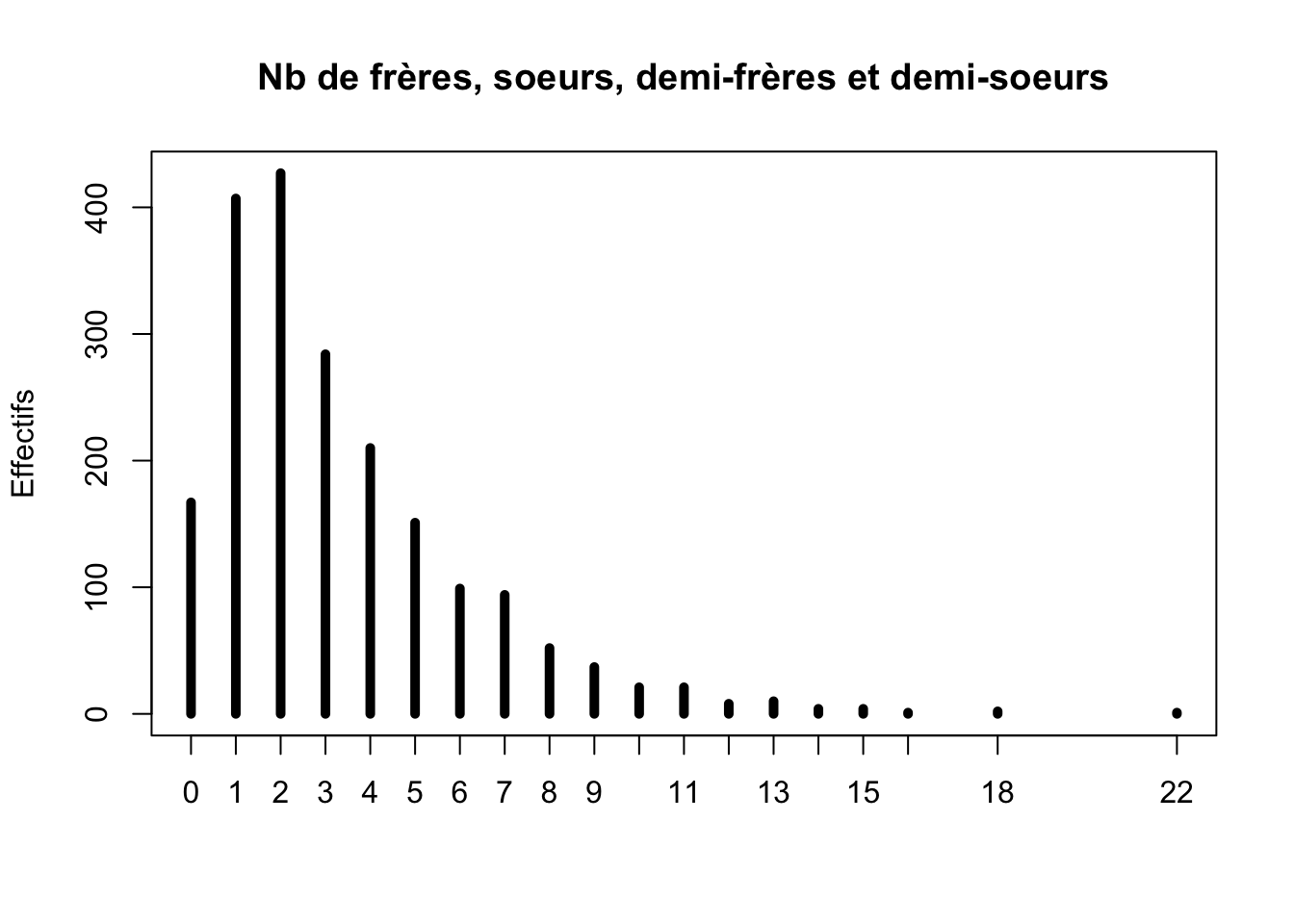
On peut aussi rajouter des points au sommet de chaque bâton (on peut également rajouter des couleurs, etc)
plot(table(hdv2003$freres.soeurs), main = "Nb de frères, soeurs, demi-frères et demi-soeurs", ylab = "Effectifs", lwd = 5, col = "orange")
points(table(hdv2003$freres.soeurs), lwd = 5, type = "p", col = "purple")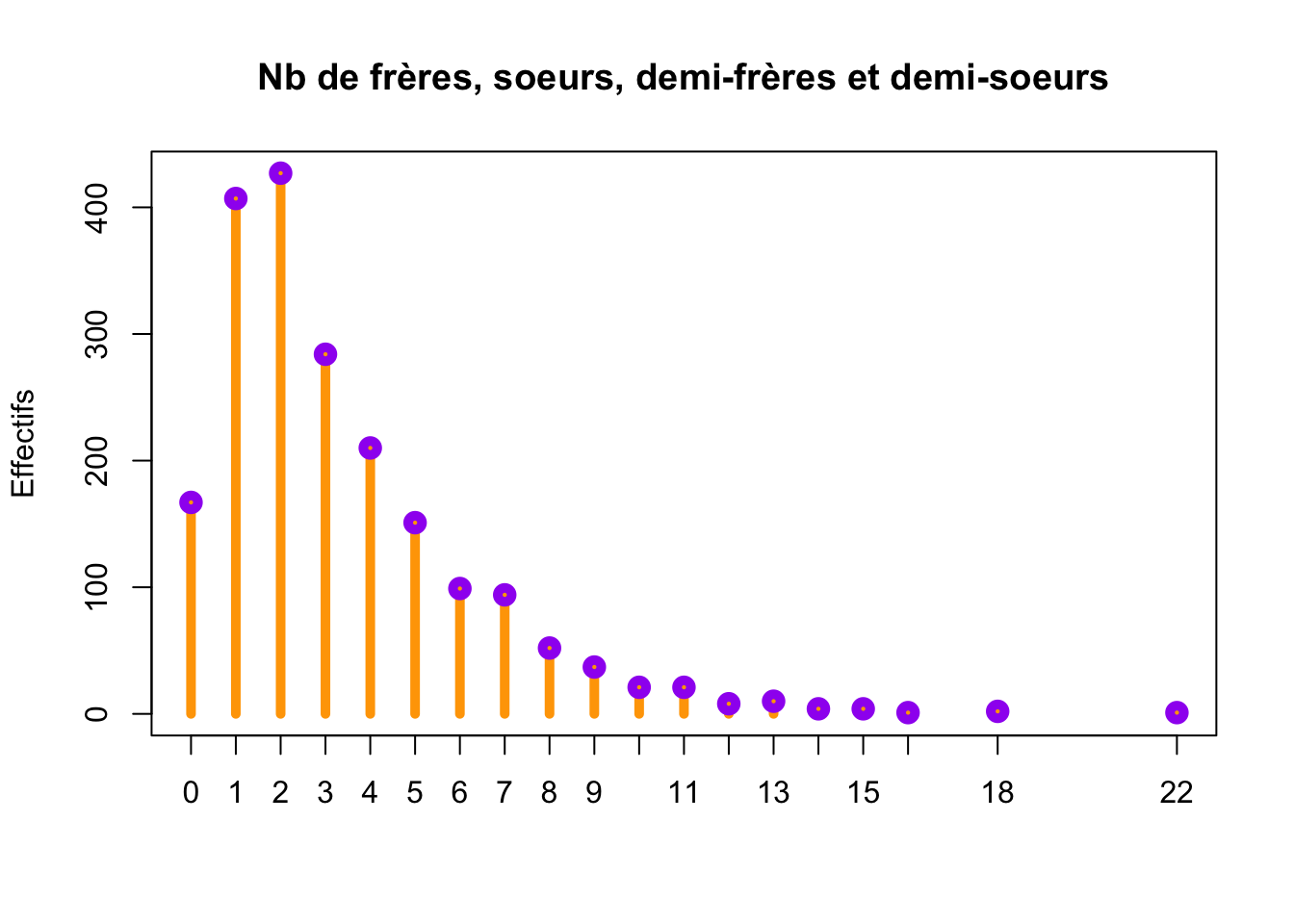
Commentaire : ce type de représentation graphique nous permet de dire que le nombre de frères et soeurs se concentre sur les valeurs 0, 1, 2, 3, 4 et 5 avec une plus forte concentration sur 1 et 2.
Histogramme
La fonction hist() de R permet de représenter l’histogramme d’une variable quantitative continue. Pour rappel, un histogramme décrit la répartition des valeurs observées pour une variable quantitative continue. Le principe de représentation d’un histogramme est le suivant : chaque rectangle possède une aire proportionnelle à l’effectif (ou la fréquence) qu’il représente. Lorsque les rectangles sont tous de même largeur (ce qui est le cas ar défaut pour la fonction hist()), les intervalles de l’axe horizontal pour lesquels on observe des rectangles de grandes hauteurs représentent les zones où les valeurs de la variable sont fortement concentrées. Les rectangles de faible hauteur identifie des intervalles où les valeurs de la variable sont faiblement concentrées. En résumé, plus la hauteur du rectangle est haute, plus les valeurs de la variable sont concentrées dans l’intervalle défini par la largeur du rectangle.
Exemple en utilisant les options par défaut :
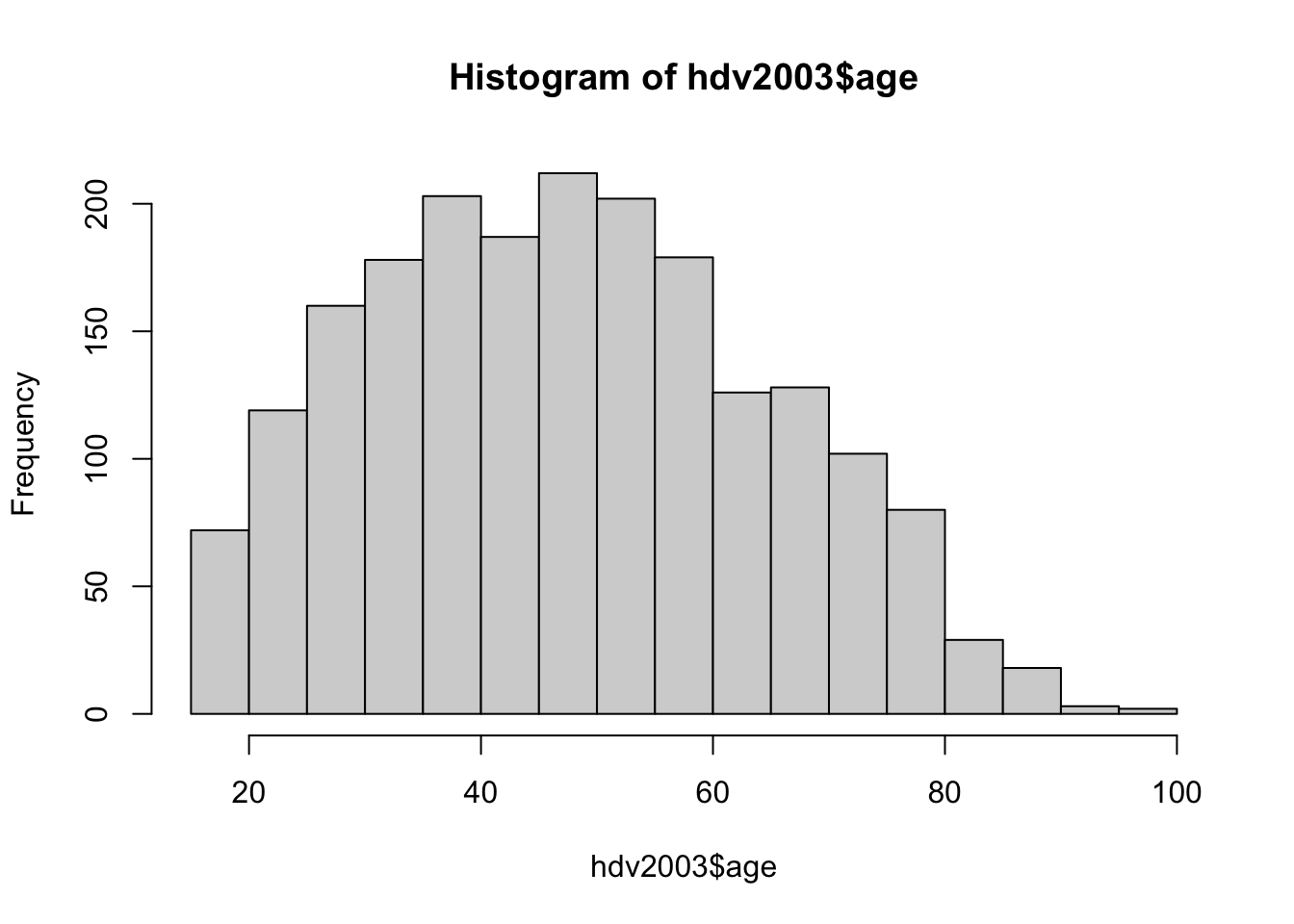
Remarque : par défaut, la fonction hist() représente les effectifs (nommé Frequency ce qui peut prêter à confusion). Il est donc important de modifier des informations pour rendre plus lisible le graphique :
hist(hdv2003$age, main = "Histogramme de la variable âge", xlab = "âge (années)", ylab = "Effectifs")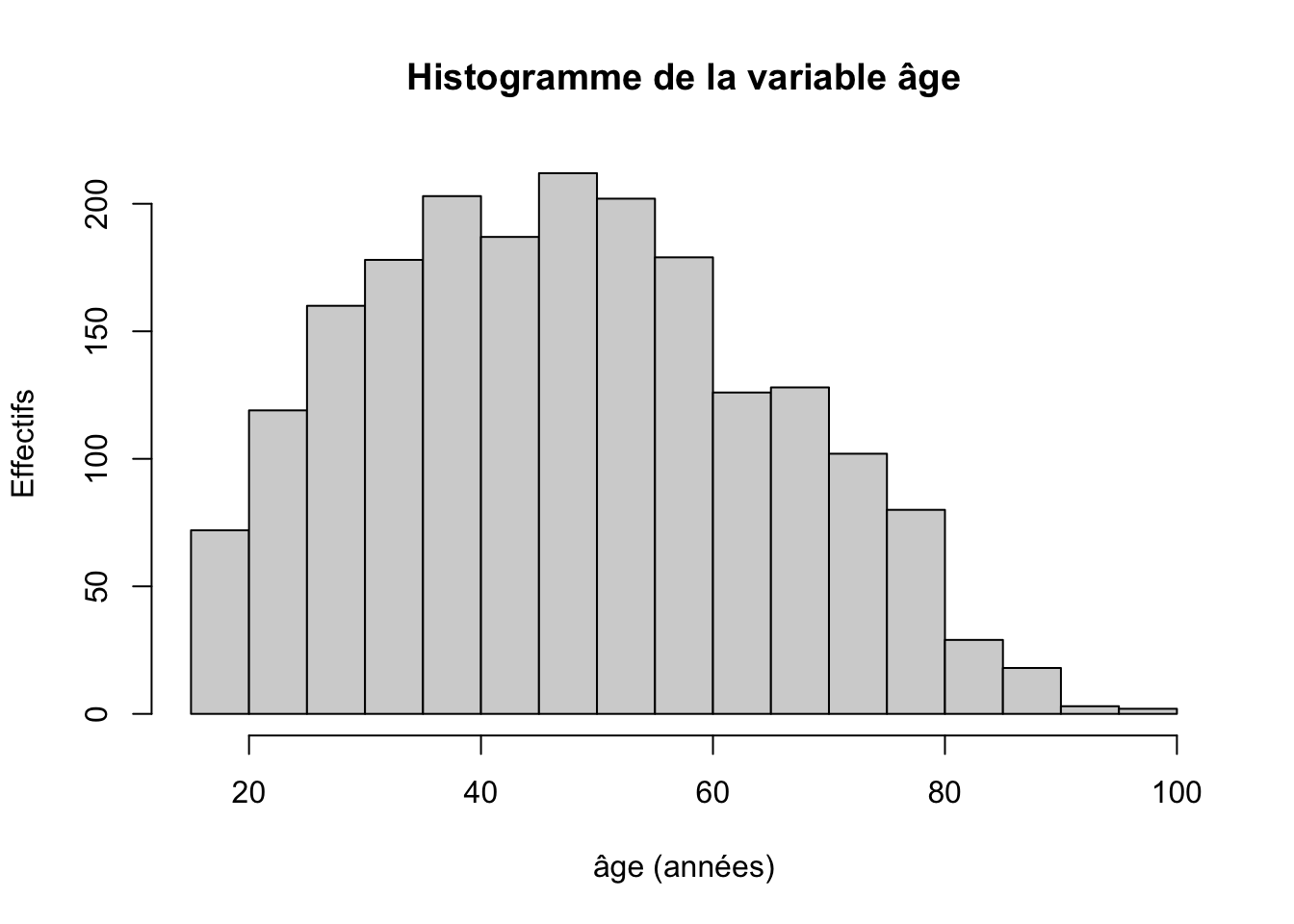
Il est possible de suggérer le nombre de classes (nombre de rectangles) avec l’option breaks (dans ce cas R propose automatiquement un nombre de classes raisonnables qui peut être différent mais qui reste proche de celui indiqué par breaks). On peut aussi augmenter la taille des caractères en rajoutant les options cex.main = 2, cex.lab = 1.5, cex.axis = 1.5 (ou bien la diminuer avec un nombre plus petit que 1) :
hist(hdv2003$age, main = "Histogramme de la variable âge", xlab = "âge (années)", ylab = "Effectifs", breaks = 10, col = "brown", cex.main = 2, cex.lab = 1.5, cex.axis = 1.5)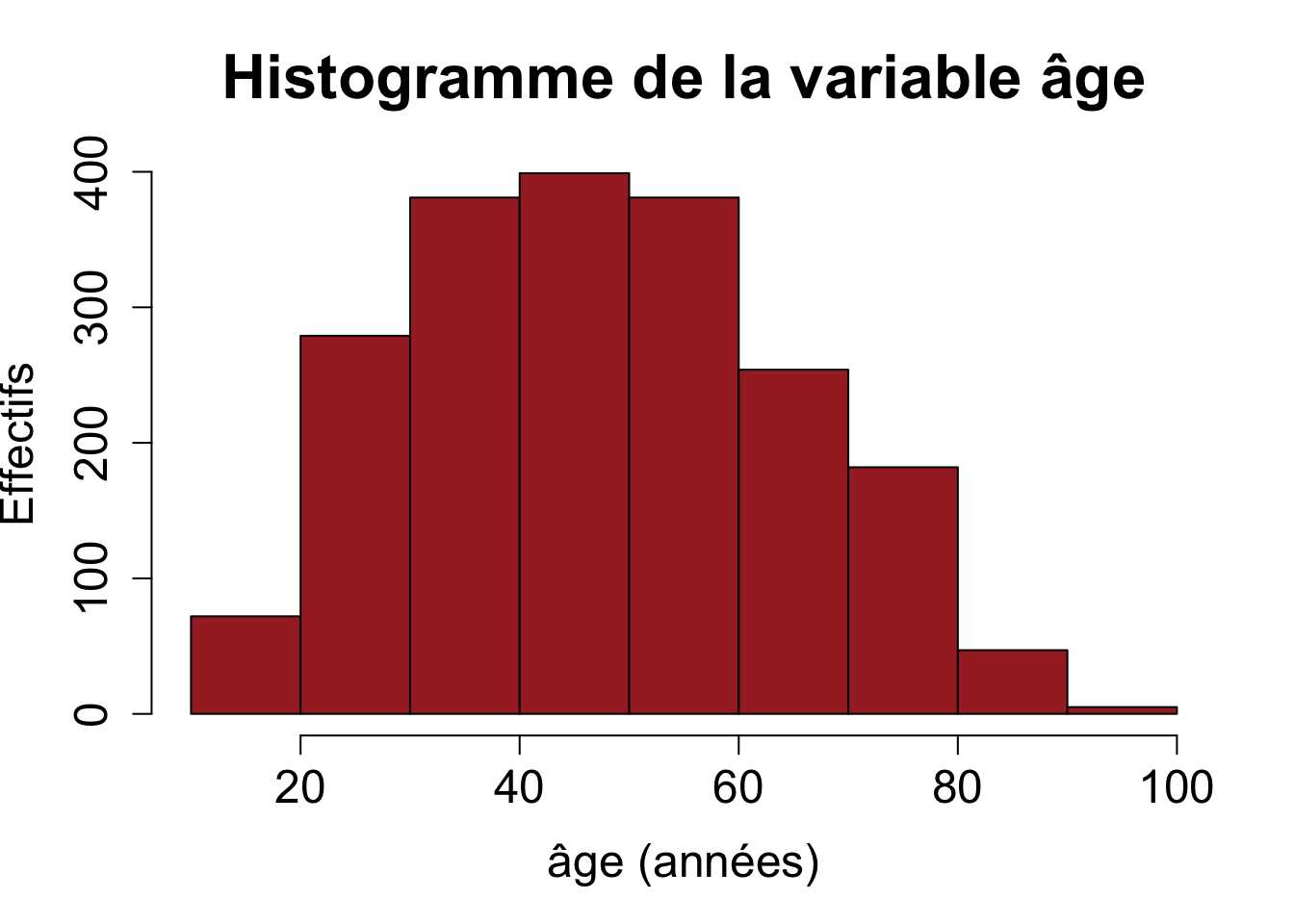
On peut aussi représenter les densités de fréquences (chaque fréquence est divisée par l’amplitude de la classe correspondante) à la place des effectifs à l’aide de l’option probability = TRUE (auquel cas la surface totale de l’histogramme est égale à 1) :
hist(hdv2003$age, main = "Histogramme de la variable âge", xlab = "âge (années)", ylab = "Densités de fréquences", breaks = 10, col = "brown", cex.main = 2, cex.lab = 1.5, cex.axis = 1.5, probability = TRUE)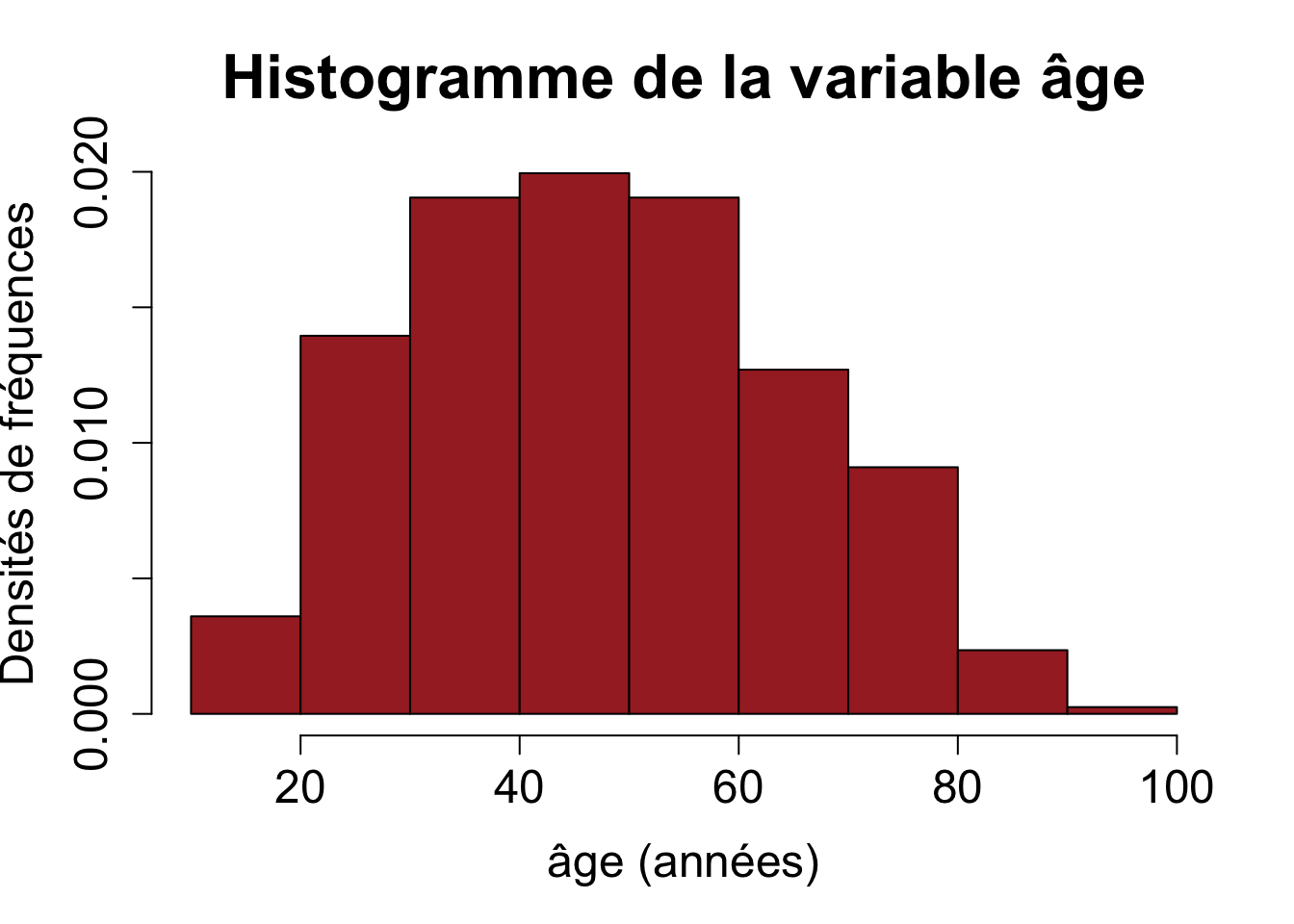
On considère maintenant les données rp2018. Pour rappel, ce jeu de données décrit 5417 villes (individus) à l’aide de 62 caractéristiques (variables) parmi lesquelles : % d’agriculteurs dans la population active (agric), % d’indépendants (indep), part des cadres (cadres), % d’ouvriers, % de propriétaires (proprio), % de logements HLM (hlm), % de locataires (locataire), % de maisons (maison).
Il peut être intéressant de représenter simultanément la distribution de plusieurs variables dans un même fenêtre graphique (pour faciliter leur comparaison). C’est l’option mfrow de la fonction par() qui permet de découper la fenêtre graphique, permettant ainsi d’y insérer plusieurs graphique. Par exemple, après s’être assuré que le jeu de données rp2018 est chargé dans votre session R, on peut produire le graphique suivant :
par(mfrow = c(2,2))
hist(rp2018$agric, main = "% agriculteurs", xlab = "%", ylab = "Dens. de fréq.", col = "brown", cex.main = 2, cex.lab = 1.5, cex.axis = 1.5, probability = TRUE)
hist(rp2018$indep, main = "% indépendants", xlab = "%", ylab = "Dens. de fréq.", col = "orange", cex.main = 2, cex.lab = 1.5, cex.axis = 1.5, probability = TRUE)
hist(rp2018$cadres, main = "% cadres", xlab = "%", ylab = "Dens. de fréq.", col = "blue", cex.main = 2, cex.lab = 1.5, cex.axis = 1.5, probability = TRUE)
hist(rp2018$etud, main = "% étudiant.e.s", xlab = "%", ylab = "Dens. de fréq.", col = "pink", cex.main = 2, cex.lab = 1.5, cex.axis = 1.5, probability = TRUE)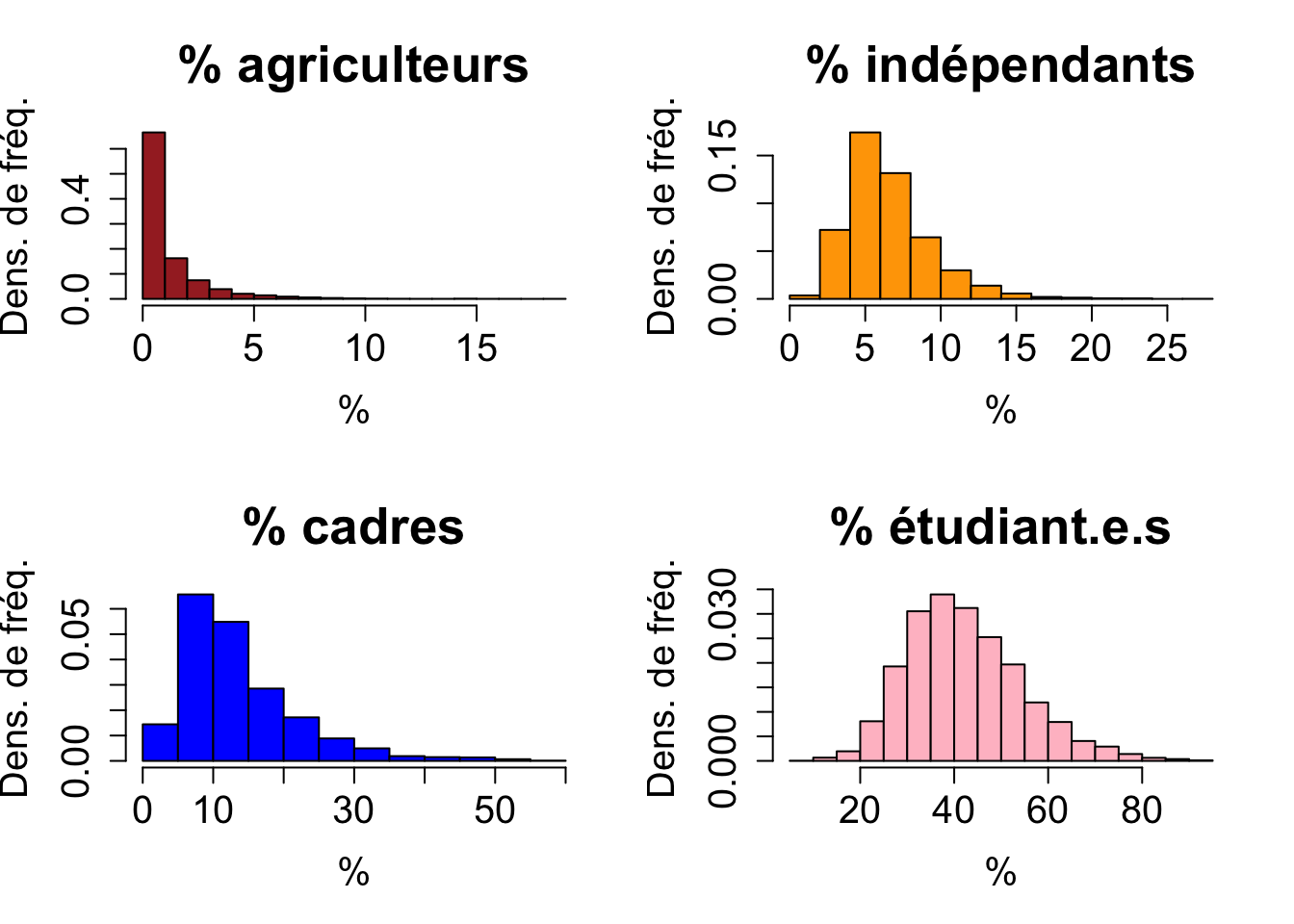
Exercice 3.6 Commenter ce graphique
Remarque : formellement, les variables quantitatives qui expriment des pourcentages issus du rapport entre deux nombres entiers ne sont pas continues. Cependant, le nombre de valeurs distinctes que fournit ce type de variables étant très important, il peut être judicieux d’un point de vue pratique de la représenter à l’aide d’histogrammes.
Exercice 3.7 Représenter simultanément les 4 variables ‘% de propriétaires’, ‘% de locataires’, ‘% de H.L.M.’ et ‘% de maisons’ ; commenter le graphique obtenu
3.3 Variables catégorielles
Diagramme en barres
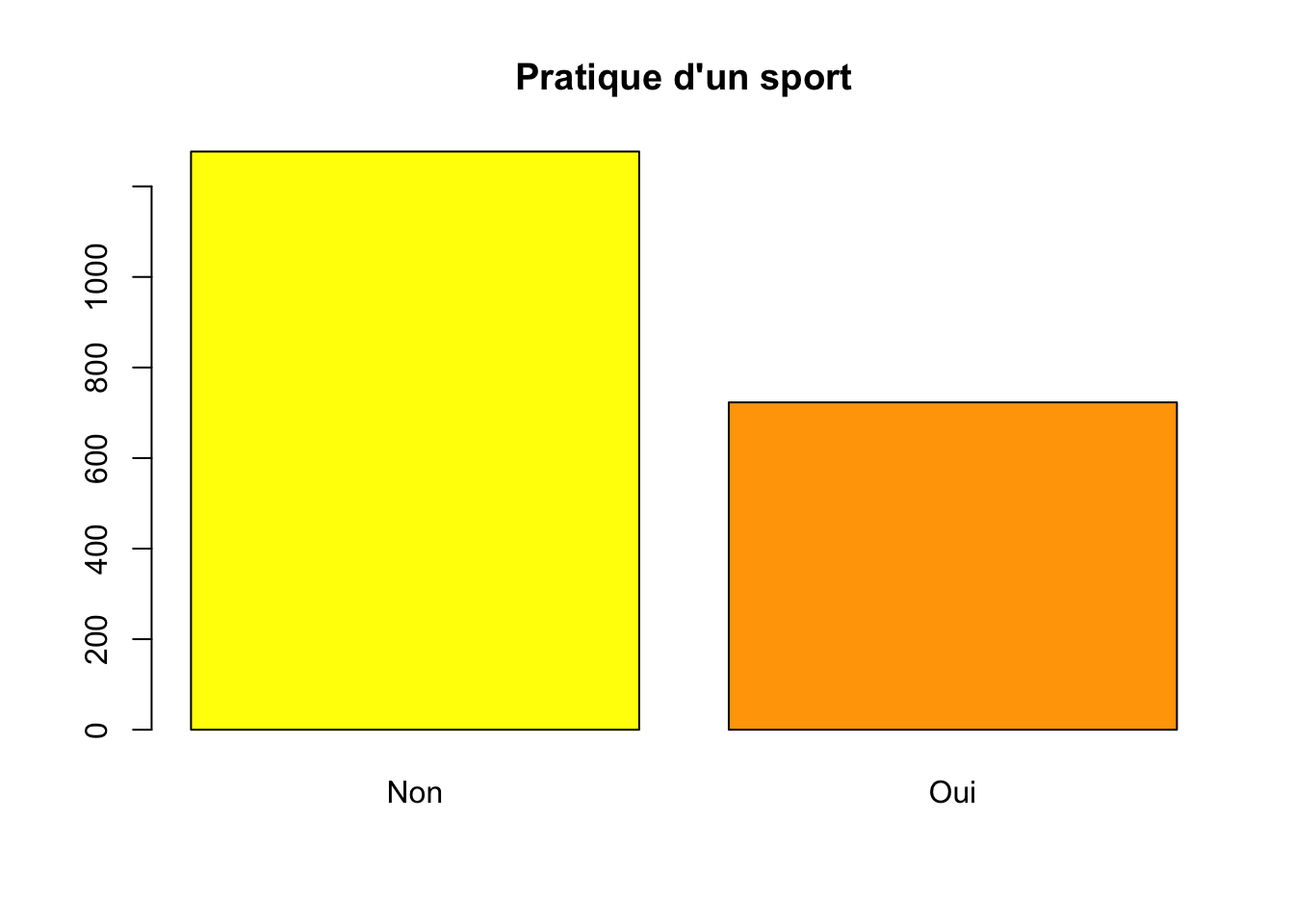
Comme précédemment, la fonction R table() fournit les effectifs de chaque modalité de la variable mise en argument. Par exemple, la commande suivante
affiche automatiquement les effectifs pour chaque modalité de la variable sport :
Non Oui
1277 723 On peut intégrer le calcul des effectif dans la fonction barplot() de R qui permet de représenter le diagramme en barres. Par exemple, la commande suivante
affiche automatiquement le graphique ci-après :
Représentation de la variable occup sans l’option names.arg
barplot(table(hdv2003$occup), main = "Occupation", col = c("yellow", "orange", "green", "blue", "pink", "purple", "brown"))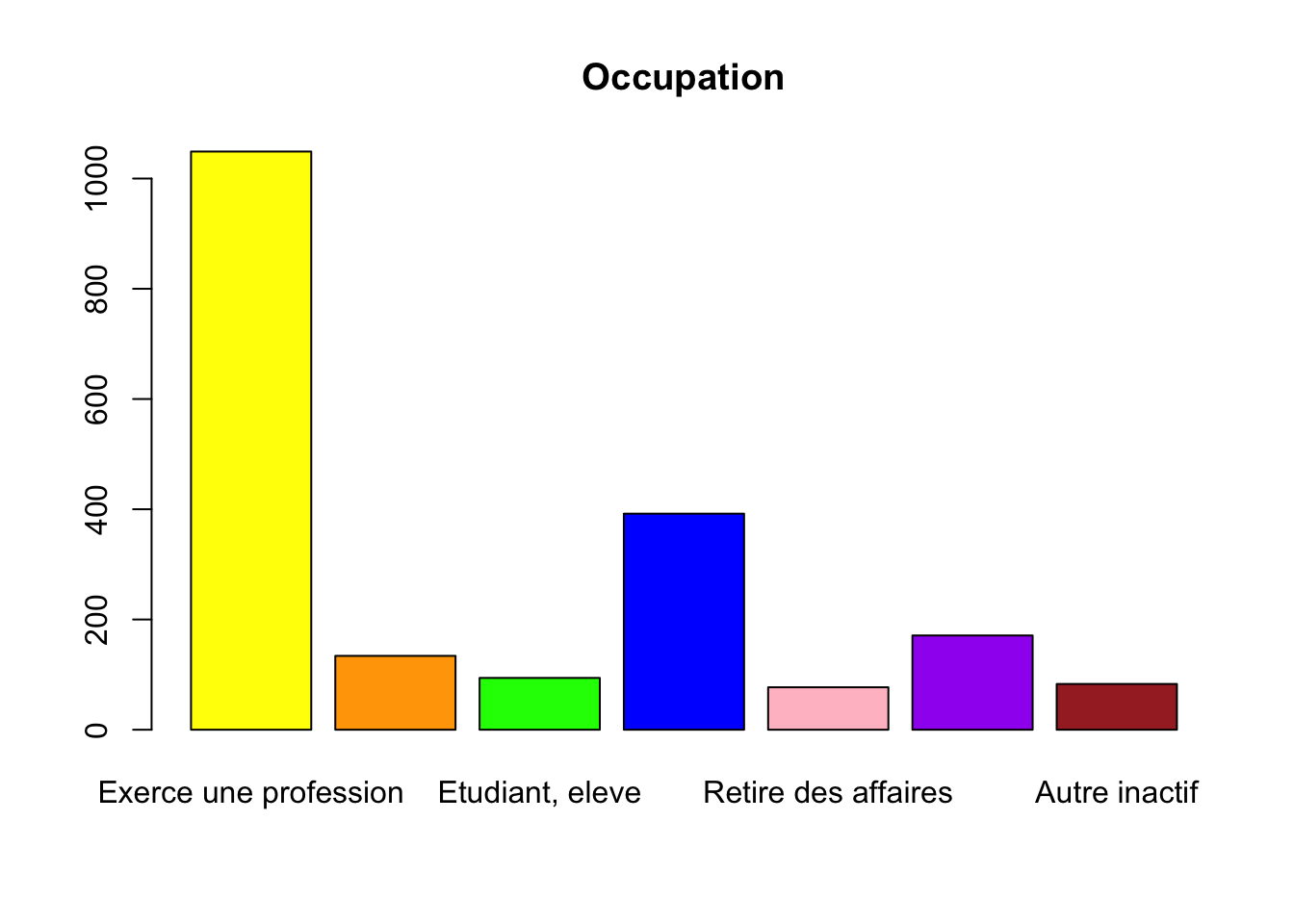
Ce graphique serait parfait si les labels de toutes les modalités étaient lisible. Or ce n’est pas le cas car les noms des modalités sont trop longs pour qu’ils puissent être placés sous chaque barre. Il est donc nécessaire de racourcir les noms des modalités pour pouvoir les afficher correctement.
La commande suivante
permet d’afficher les labels des modalités de la variable occup :
Exerce une profession Chomeur Etudiant, eleve
1049 134 94
Retraite Retire des affaires Au foyer
392 77 171
Autre inactif
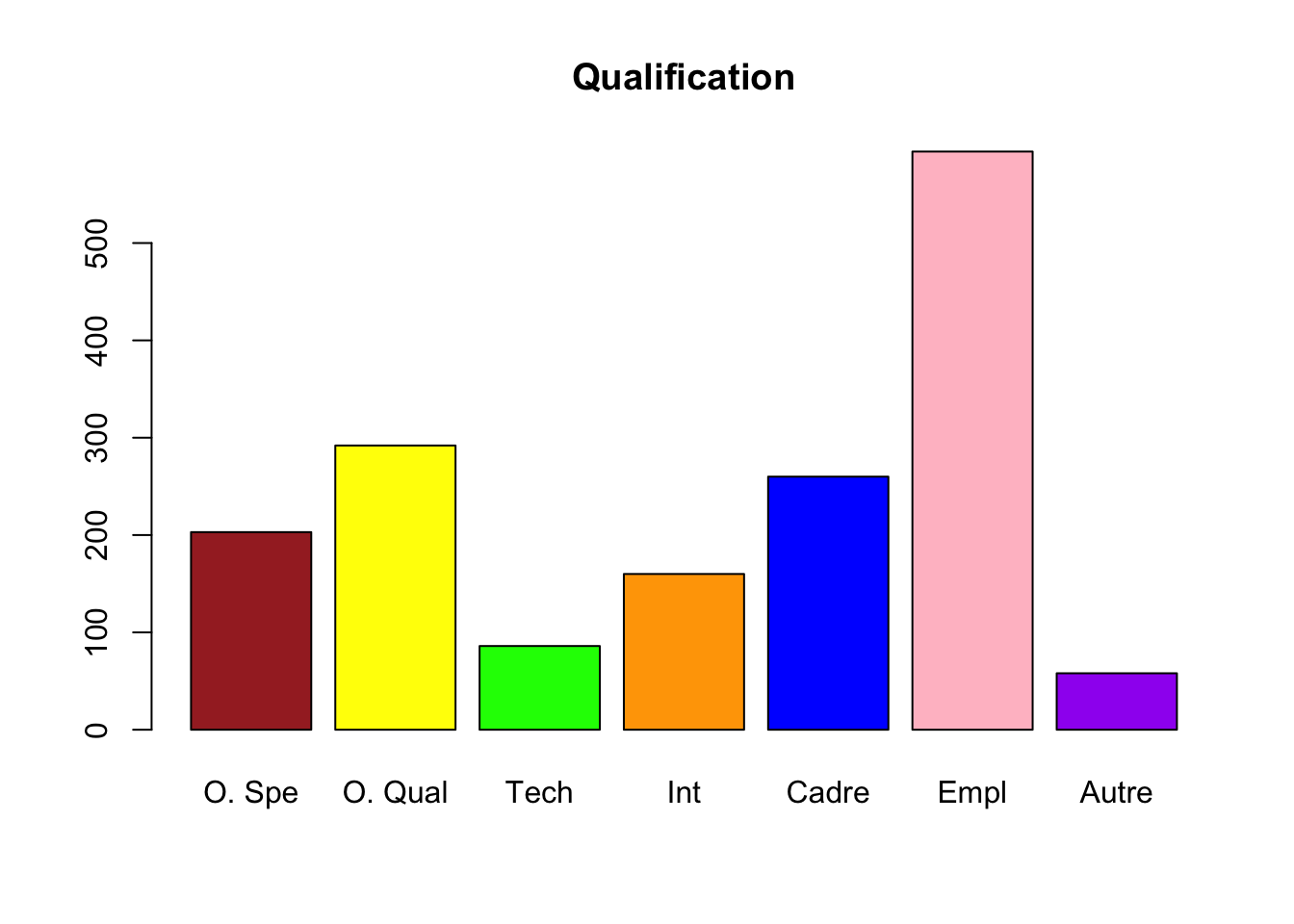
83 Lorsque les noms des modalités sont trop longs, on peut les renommer dans la fonction barplot() à l’aide de l’option names.arg. étape 1. création d’un vecteur (ici Occup) contenant de nouveaux noms/labels pour les modalités :
étape 2. Utilisation de la fonction barplot() en rajoutant l’option names.arg = Occup :
barplot(table(hdv2003$occup), main = "Occupation", col = c("yellow", "orange", "green", "blue", "pink", "purple", "brown"), names.arg = Occup)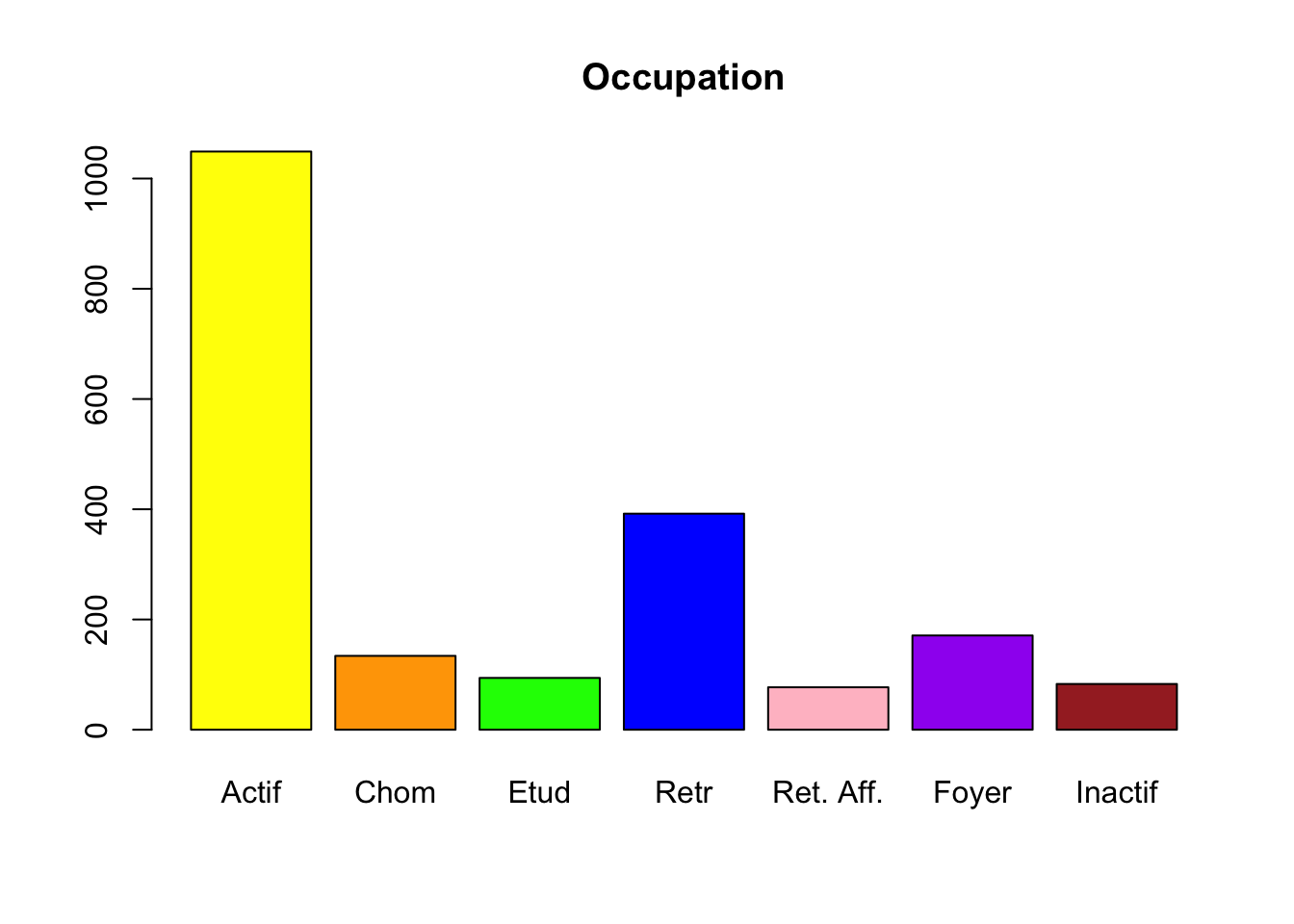
Exercice 3.8 Réaliser le graphique suivant :
Représentation simultanée de plusieurs variables qualitatives possédant les mêmes modalités
Rappel : la fonction table() fournit les effectifs pour chaque modalité de la variable.
étape 1 : construction d’une matrice dont chaque colonne contient les effectifs des modalités d’une variable qualtitative. Par exemple, la commande suivante
créée une matrice 2 lignes et 2 colonnes appelée DATA (rappel : la fonction cbind permet de coller deux vecteurs pour construire une matrice). En tapant son nom,
la matrice ainsi créée s’affiche :
[,1] [,2]
Non 1119 1776
Oui 881 224étape 2 : on peut représenter simultanément ces deux variables à l’aide de la commande :
barplot(DATA, main = "2 variables simultanément", names.arg = c("cuisine", "pêche-chasse"), col = c("yellow", "orange"), legend.text = T)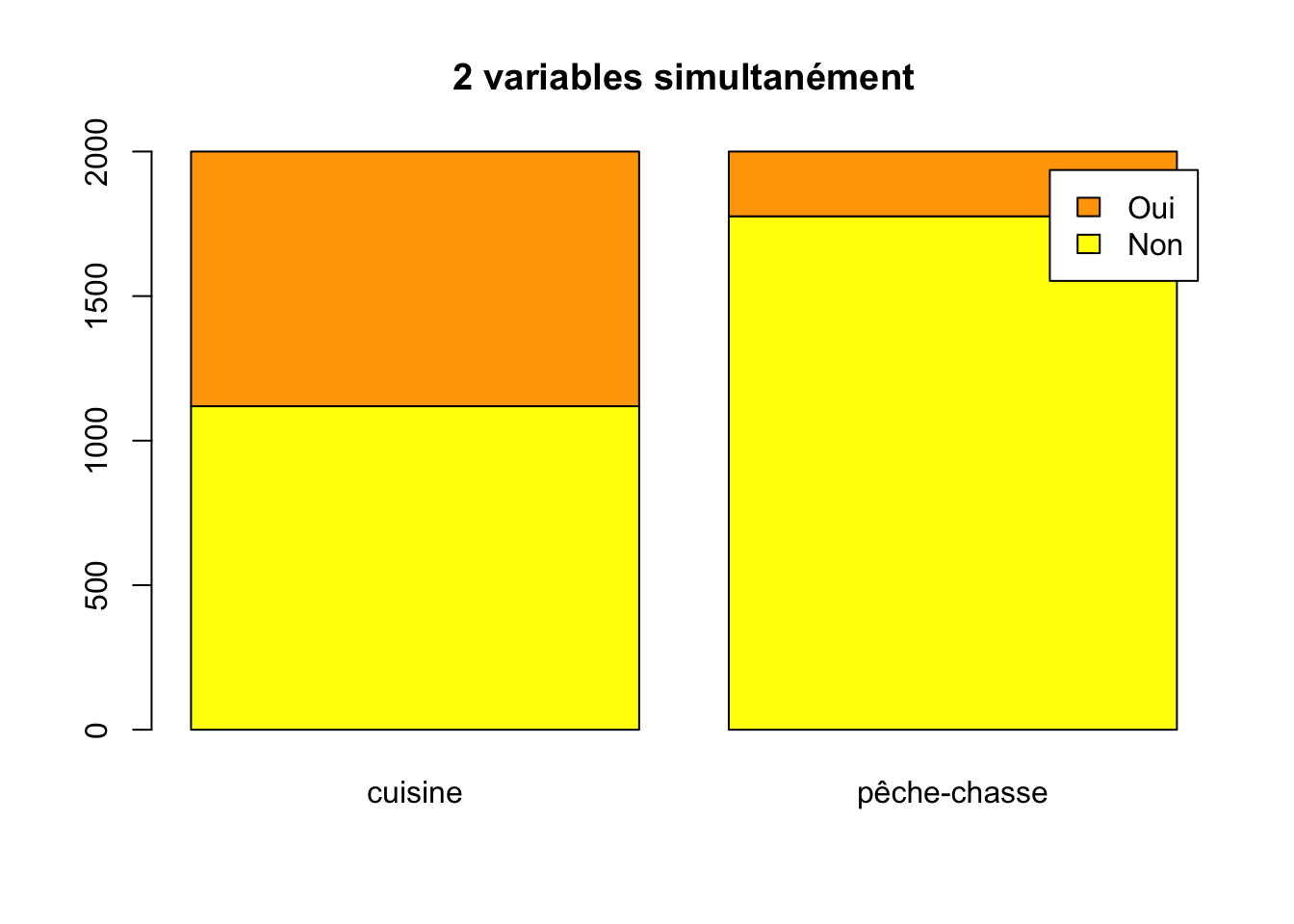
Remarque : l’option legend.text = T permet d’afficher la légende
Pour éviter le chevauchement de la légende avec les barres, il suffit de diminuer la largeur des barres à l’aide de l’option xlim
barplot(DATA, main = "2 variables simultanément", names.arg = c("cuisine", "pêche-chasse"), col = c("yellow", "orange"), legend.text = T, xlim = c(0, 3))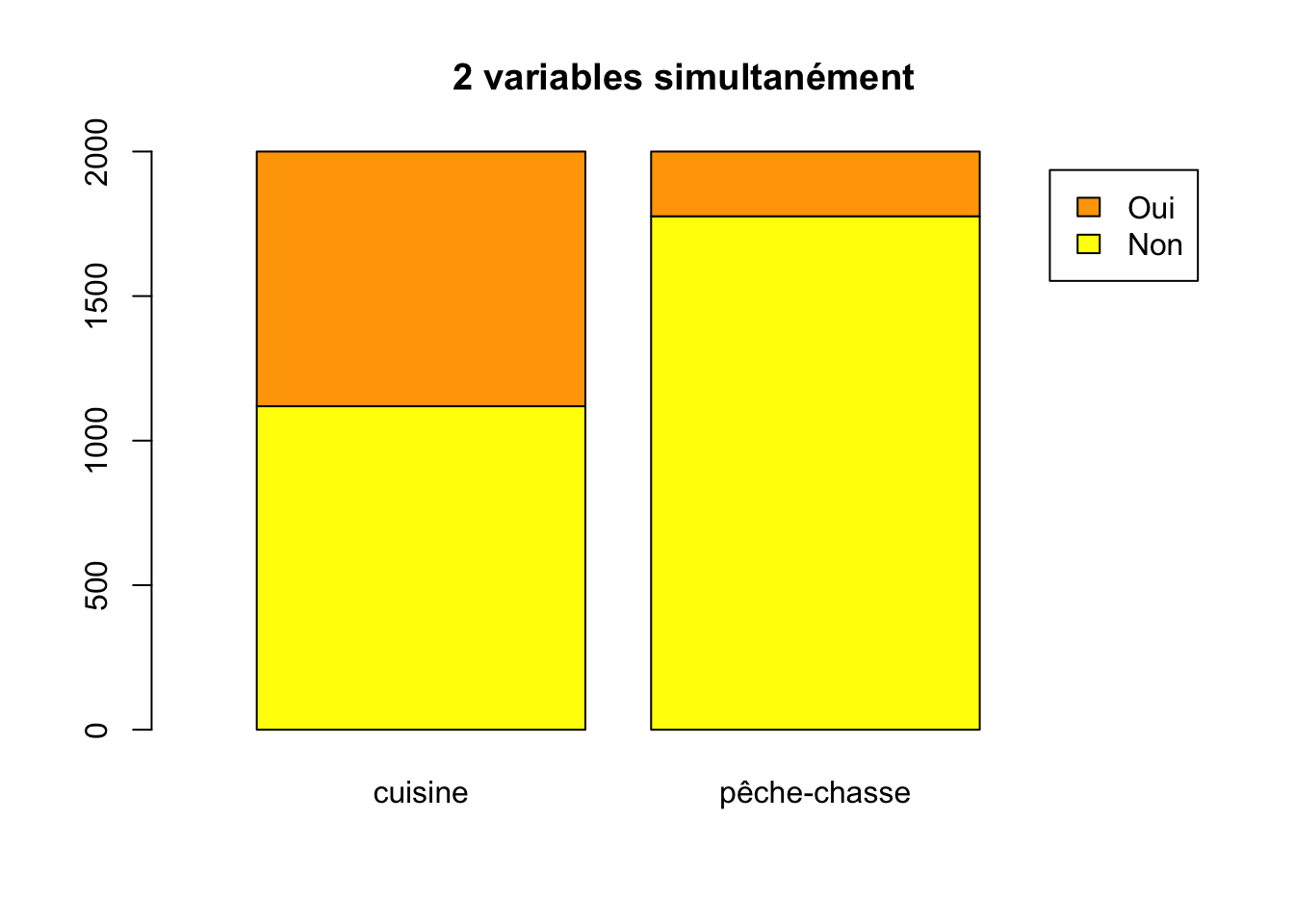
Une option de la fonction barplot() que l’on peut utiliser dans ce type de graphique est l’option beside qui peut prendre les valeurs F (FALSE) ou T (TRUE) ; par defaut, beside=F
barplot(DATA, main = "2 variables simultanément", names.arg = c("cuisine", "pêche-chasse"), col = c("yellow", "orange"), legend.text = T, beside = T)
Réduction de la largeur des barres avec l’option xlim de la fonction barplot
barplot(DATA, main = "2 variables simultanément", names.arg = c("cuisine", "pêche-chasse"), col = c("yellow", "orange"), legend.text = T, beside = T, xlim = c(0,8))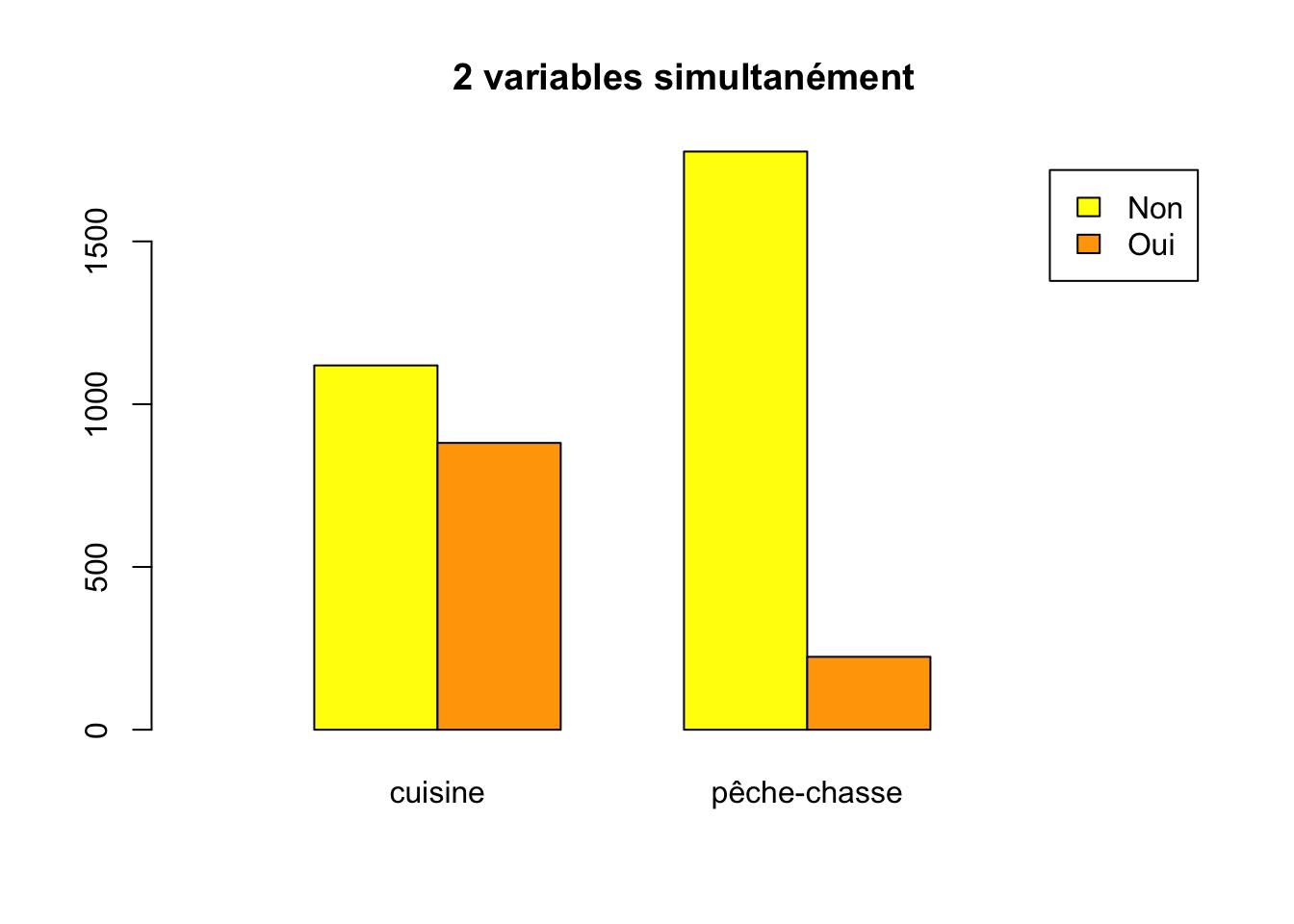
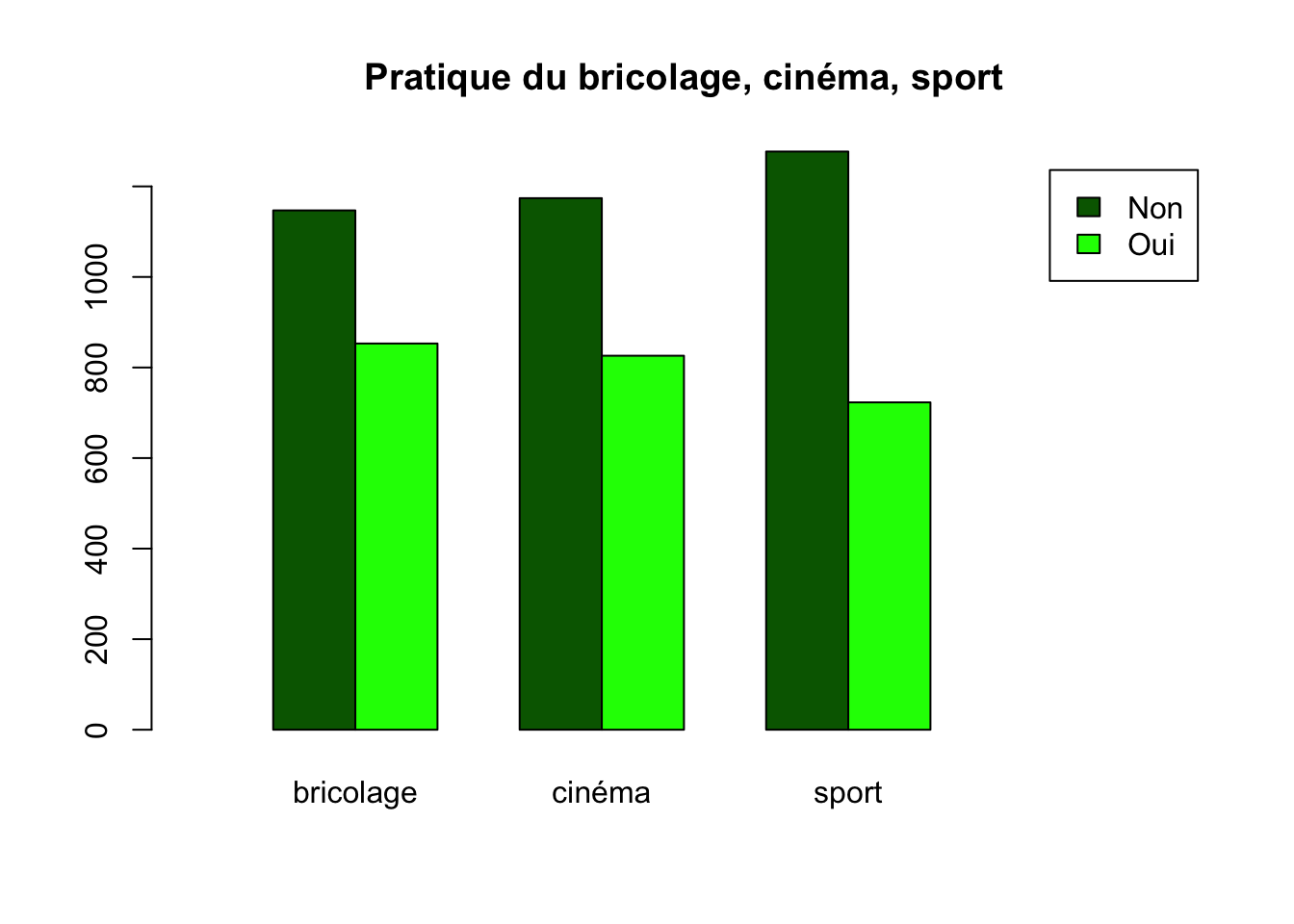
Exercice 3.9 Réaliser le graphique suivant :
Camemberts
Rappel : un camembert permet de représenter la distribution d’une variable qualitative. Un cercle est divisé en autant de secteurs que de modalités ; l’angle de chaque secteur est proportionnel à l’effectif de la modalité qu’il représente.
C’est la fonction pie() de R qui permet de représenter un camembert. Par exemple, la commande suivante rezprésente le camembert pour la variable occupation :
pie(table(hdv2003$occup), main = "Occupation", labels = c("En activité", "Chomeur", "Etud", "Retraité", "Ret. Aff.", "Au foyer", "autre inactif"))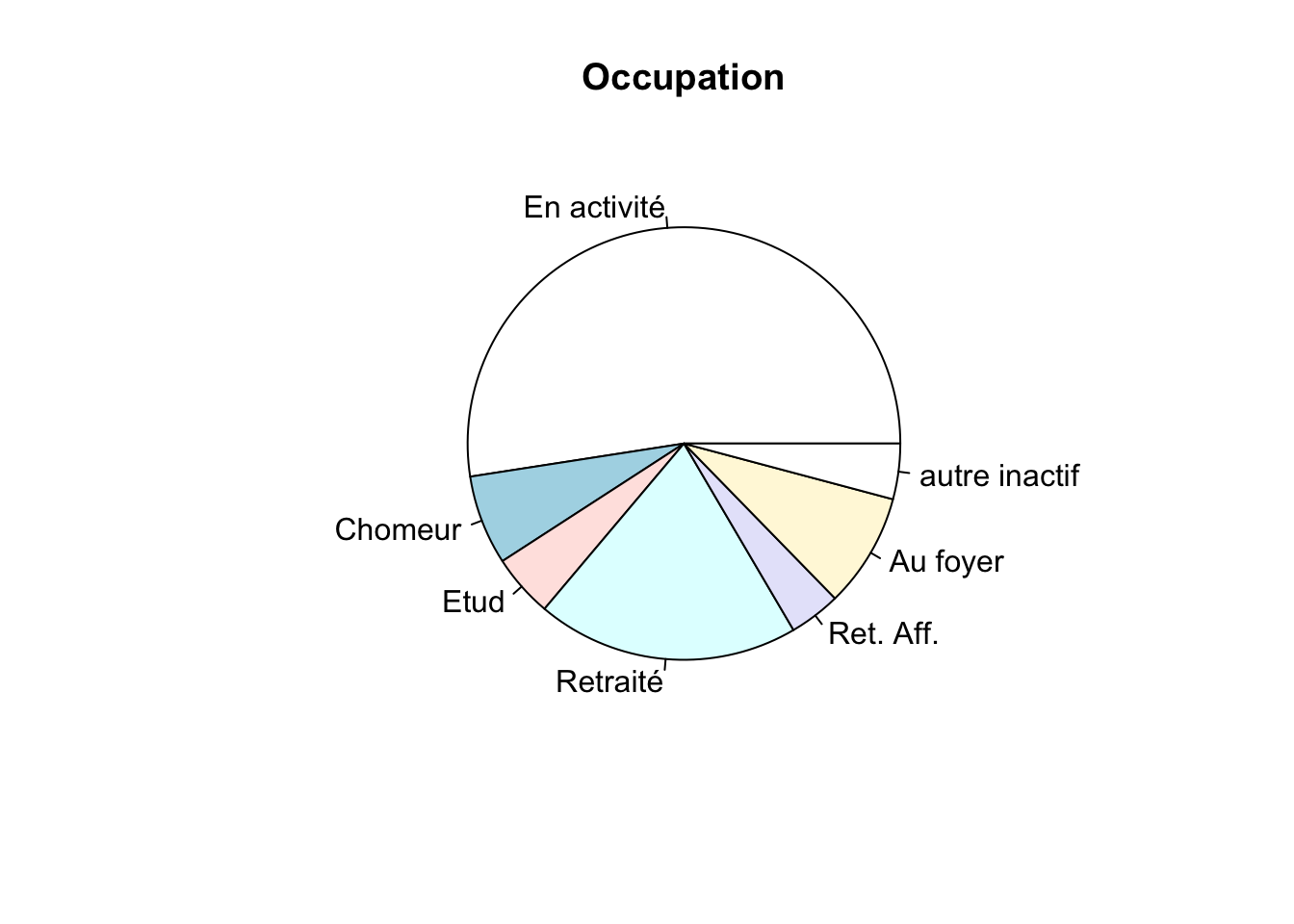
Par défaut, la 1ère modalité “En activité” démarre à l’horizontale puis les modalités s’enchaînent dans le sens contraire des aiguilles d’une montre.
Rappel : la fonction R table() calcule les effectifs pour chaque modalité
Ajout de l’option init.angle = 90 de la fonction R pie :
pie(table(hdv2003$occup), main = "Occupation", labels = c("En activité", "Chomeur", "Etud", "Retraité", "Ret. Aff.", "Au foyer", "autre inactif"), init.angle = 90)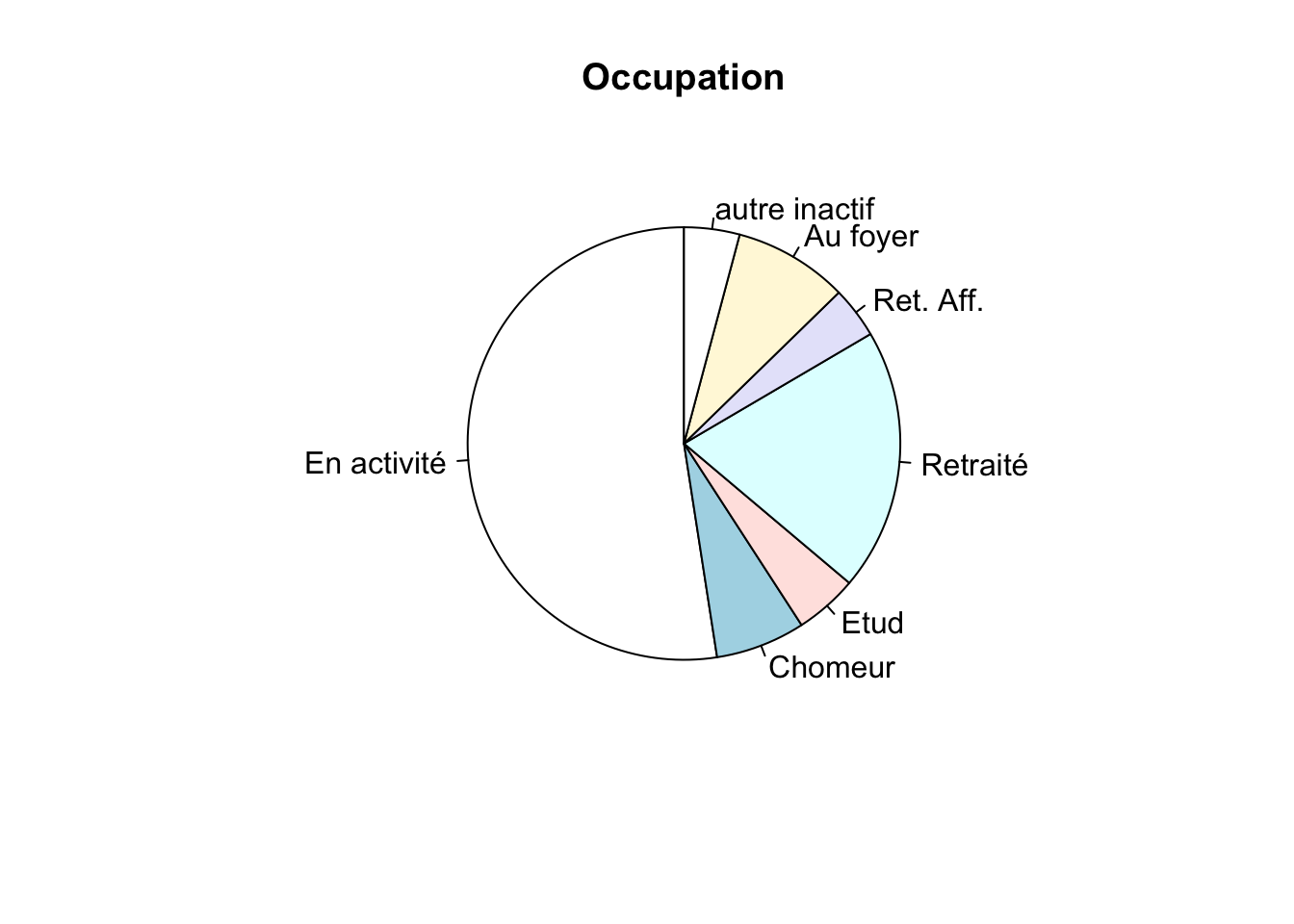
La 1ère modalité “En activité” démarre à 90° (c’est-à-dire à la verticale) puis les modalités s’enchaînent dans le sens contraire des aiguilles d’une montre.
Exercice 3.10 Réaliser le graphique suivant :
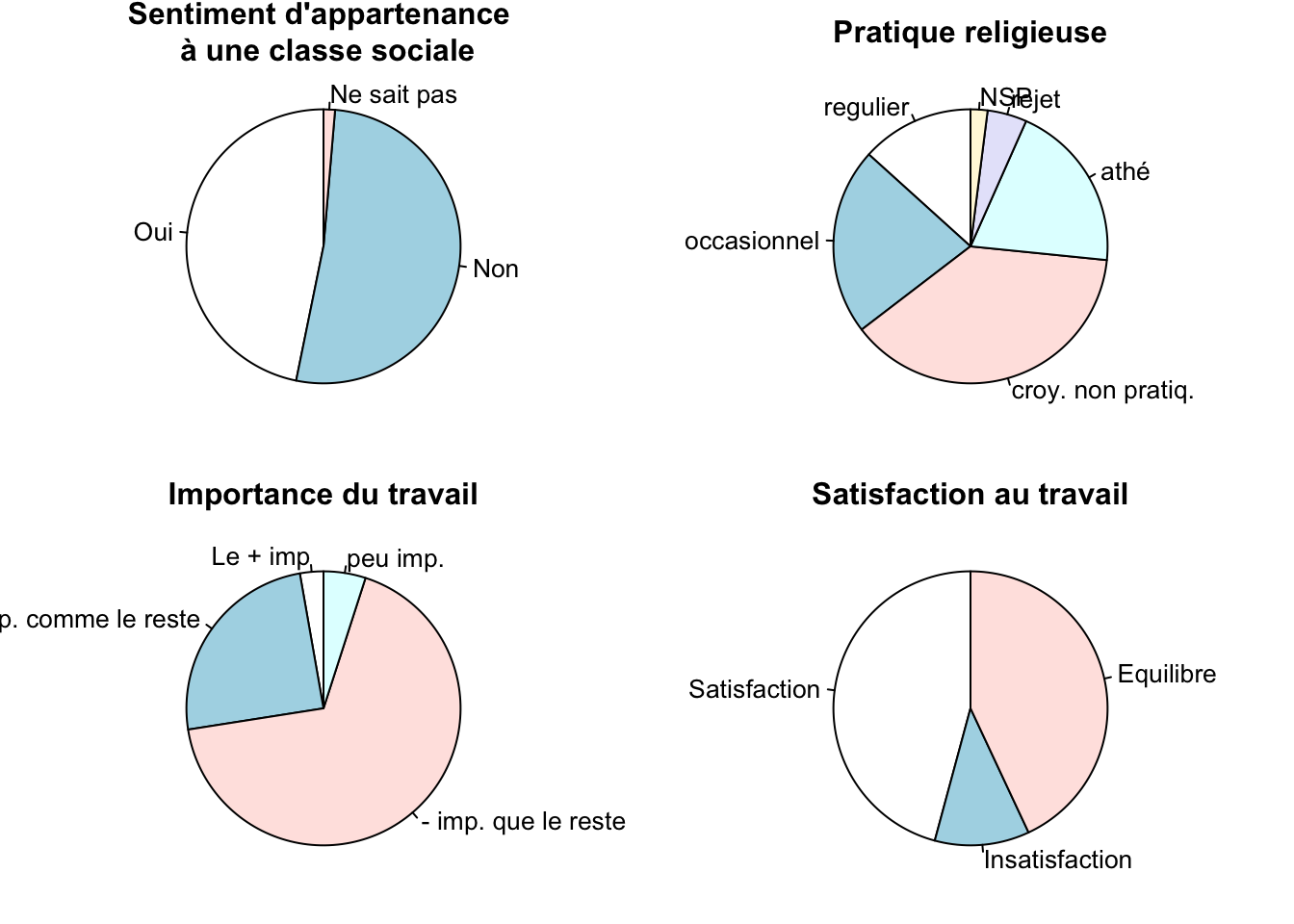
Remarque : par défaut, les graphiques utilisent des marges en bas, à gauche, à droite et en haut. L’option mar de la fonction R par() permet de controler ces marges. On affecte à l’option mar 4 entiers correspondant à un nombre de lignes pour chaque marge. Par exemple, si on tape mar = c(1,1,2,1), on aura une marge d’1 ligne en dessous, une marge d’1 ligne à gauche, une marge de 2 lignes en haut et une marge d’1 ligne à droite. L’ajout de cette option mar = c(1,1,2,1) permet de mieux utiliser l’espace de la fenêtre graphique afin de rendre les camemberts beaucoup plus lisibles.
Relancer le même graphique en remplaçant la 1ère ligne de commande
par