Chapter 2 Introduction à R et RStudio
2.1 Présentation du logiciel R et de son environnement RStudio
R?
R est un langage de programmation gratuit spécialisé dans le traitement de données et plus généralement dans ce qu’on appelle la Science des Données. Ses fonctionnalités permettent aussi bien la mise en forme des données que les traitements statistiques les plus pointus
R possède une structure modulaire :
- R s’utilise à l’aide d’instructions se présentant sous forme de ligne(s) de commandes appelées script R (ou code R)
- le script R obéit à une syntaxe précise comme tout langage de programmation
- R contient par défaut un ensemble de fonctions de base
- ce noyau de base peut être enrichi par des modules selon les besoins de l’utilisateur ; chaque module, appelé package, regroupe un ensemble de fonctions dédiées à un usage spécifique
- les packages peuvent être installés facilement grâce à des sites mirroirs localisés un peu partout dans le monde (dont 4 villes en France : Lyon, Marseille, Montpellier et Paris)
- R permet la mise en forme de données, la réalisation de graphiques, la mise en oeuvre de traitements statistiques (statistique descriptive, régression linéaire, statistique exploratoire multidimensionnelle, statistique inférentielle, méthodes de classification, traitement d’images, simulation de données, analyse de textes,…)
- R est développé par l’ensemble de la communauté internationale des statisticien.ne.s (essentiellement universitaire ce qui explique sa gratuité). Toute nouvelle méthode statistique est rapidement disponible sous forme de package. R est le leader des logiciels dédiés aux traitements statistiques et plus généralement à l’apprentissage automatique.
RStudio?
RStudio est un environnement multifenêtre facilitant l’usage du logiciel R :
- fenêtre console dans laquelle le script R est exécuté ligne par ligne (on ne peut exécuter qu’une ligne de script R à la fois)
- fenêtre R script : cette fenêtre est positionnée automatiquement au-dessus de la console lorsqu’on demande sa création
- fenêtre Environnement (onglet situé à droite en haut) : cette fenêtre affiche tous les objets R créés. Il s’agit du répertoire de travail R c’est-à-dire l’endroit où tous les objets créés sont stockés physiquement. Pour connaître le nom du répertoire de travail, il suffit d’exécuter dans la console la commande getwd() (tapez getwd() puis tapez sur retour pour l’exécuter) ; le nom complet du répertoire de travail apparaît.
Remarque : dans la commande getwd(), wd est l’abréviation de “working directory” qui se traduit par “répertoire de travail” - fenêtre Plots (onglet situé à droite) : c’est dans cette fenêtre que les graphiques sont affichés
- fenêtre Help (onglet situé à droite) : c’est dans cette fenêtre que s’affiche la description d’une fonction R
Installation de R et RStudio
Pour celles et ceux qui souhaitent utiliser un ordinateur personnel, il est nécessaire que vous installiez le logiciel R puis son environnement de développement RStudio. Dans ce but, le site https://quanti.hypotheses.org/1813 détaille les étapes qui permettent d’installer sans peine ces deux logiciels.
2.2 Prise en main de la syntaxe R
Ce que vous devez faire
Les premières séances ont pour objectif de vous familiariser avec la syntaxe de R. Cette étape est fondamentale pour vous approprier le logiciel R. Votre travail consiste à :
- exécuter une par une les lignes de commandes qui vous sont proposées (écrire la ligne de commande proposée dans la console puis exécuter la en appuyant sur la touche retour)
- comprendre le(s) résultat(s) produit(s)
Il ne s’agit pas d’un concours de vitesse!
Objets simples, types et affectation
Remarque : tout texte commençant par le symbole # est interprété comme un commentaire ; il n’est pas exécuté
# opérations arithmétiques avec les opérateurs logiques
vrai * vrai
vrai * faux
vrai + vrai
vrai + faux
3 * vrai + 2 * faux
(y > 10) + 5# les différents types d'objet
is.numeric(y)
is.numeric(vrai)
is.logical(vrai)
is.character(phrase)
is.character(faux)Le symbole “=” (qui peut être remplacé de façon strictement équivalente par le symbole “<-”) permet d’affecter à un objet un contenu. Par exemple, la commande x = 2 crée l’objet x qui contient la valeur 2 (l’objet x apparaît si vous cliquez sur l’onglet Environnement situé sur le panneau de droite en haut). Lorsqu’on exécute la commande x = 2 rien n’est affiché. En revanche, lorsqu’on exécute x (c’est-à-dire lorsqu’on écrit x puis on appuie sur la touche retour), le contenu de l’objet est affiché.
2.3 Vecteurs
Vecteurs numériques
# création du vecteur "Tailles"
Tailles = c(167, 192, 173, 174, 172, 167, 171, 185, 163, 170)
# affichage du vecteur "Tailles"
TaillesVecteurs de type factor
Le vecteur Reponse est par défaut de type character. Pour rendre plus explicite son résumé, R met à disposition de l’utilisateur un nouveau type de données appelé factor avec les fonctions dédiées factor(), as.factor(), is.factor() et levels. Ce type est particulièrement bien adapté aux variables catégorielles.
Création d’un vecteur de type factor
# création d'un vecteur de type "factor"
Reponse_f = factor(c("Bac+2", "Bac", "CAP", "Bac", "Bac", "CAP", "BEP"))
# affichage de l'objet
Reponse_f
# affichage des niveaux du facteur (modalités)
levels(Reponse_f)
# résumé explicite du contenu
summary(Reponse_f)
# résumé d'un vecteur de type "character" (moins explicite)
summary(Reponse)
# transformation d'un vecteur de type "character" en facteur
Reponse_fbis = as.factor(Reponse)
Reponse_fbis2.4 Matrices (tableaux lignes x colonnes)
L’observation de caractéristiques (i.e. variables quantitatives ou qualitatives) mesurées sur des individus produit des tableaux lignes x colonnes. Chaque ligne correspond à un individu et chaque colonne correspond à une variable (caractéristique). Prenons par exemple le tableau suivant donnant pour les températures mensuelles moyennes sur 30 ans pour 15 villes françaises :
| Janv | Fevr | Mars | Avri | Mai | Juin | juil | Aout | Sept | Octo | Nove | Dece | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bordeaux | 5.6 | 6.6 | 10.3 | 12.8 | 15.8 | 19.3 | 20.9 | 21.0 | 18.6 | 13.8 | 9.1 | 6.2 |
| Brest | 6.1 | 5.8 | 7.8 | 9.2 | 11.6 | 14.4 | 15.6 | 16.0 | 14.7 | 12.0 | 9.0 | 7.0 |
| Clermont | 2.6 | 3.7 | 7.5 | 10.3 | 13.8 | 17.3 | 19.4 | 19.1 | 16.2 | 11.2 | 6.6 | 3.6 |
| Grenoble | 1.5 | 3.2 | 7.7 | 10.6 | 14.5 | 17.8 | 20.1 | 19.5 | 16.7 | 11.4 | 6.5 | 2.3 |
| Lille | 2.4 | 2.9 | 6.0 | 8.9 | 12.4 | 15.3 | 17.1 | 17.1 | 14.7 | 10.4 | 6.1 | 3.5 |
| Lyon | 2.1 | 3.3 | 7.7 | 10.9 | 14.9 | 18.5 | 20.7 | 20.1 | 16.9 | 11.4 | 6.7 | 3.1 |
| Marseille | 5.5 | 6.6 | 10.0 | 13.0 | 16.8 | 20.8 | 23.3 | 22.8 | 19.9 | 15.0 | 10.2 | 6.9 |
| Montpellier | 5.6 | 6.7 | 9.9 | 12.8 | 16.2 | 20.1 | 22.7 | 22.3 | 19.3 | 14.6 | 10.0 | 6.5 |
| Nantes | 5.0 | 5.3 | 8.4 | 10.8 | 13.9 | 17.2 | 18.8 | 18.6 | 16.4 | 12.2 | 8.2 | 5.5 |
| Nice | 7.5 | 8.5 | 10.8 | 13.3 | 16.7 | 20.1 | 22.7 | 22.5 | 20.3 | 16.0 | 11.5 | 8.2 |
| Paris | 3.4 | 4.1 | 7.6 | 10.7 | 14.3 | 17.5 | 19.1 | 18.7 | 16.0 | 11.4 | 7.1 | 4.3 |
| Rennes | 4.8 | 5.3 | 7.9 | 10.1 | 13.1 | 16.2 | 17.9 | 17.8 | 15.7 | 11.6 | 7.8 | 5.4 |
| Strasbourg | 0.4 | 1.5 | 5.6 | 9.8 | 14.0 | 17.2 | 19.0 | 18.3 | 15.1 | 9.5 | 4.9 | 1.3 |
| Toulouse | 4.7 | 5.6 | 9.2 | 11.6 | 14.9 | 18.7 | 20.9 | 20.9 | 18.3 | 13.3 | 8.6 | 5.5 |
| Vichy | 2.4 | 3.4 | 7.1 | 9.9 | 13.6 | 17.1 | 19.3 | 18.8 | 16.0 | 11.0 | 6.6 | 3.4 |
Ici, les individus en ligne représentent les 15 villes et on dispose de 12 variables en colonnes correspondant aux températures mensuelles moyennes sur 30 ans (12 mois \(\longrightarrow\) 12 variables).
Création d’une matrice
On peut décider de saisir à la main que la partie bleue de ce tableau (nous verrons ultérieurement d’autres moyens pour saisir automatiquement l’ensemble des données contenues dans ce tableau). Une méthode consiste à créer une matrice (à l’aide de la fonction R matrix) contenant ces données puis de lui affecter des noms de lignes et de colonnes pour conserver la lisibilité des données :
# Création d'un vecteur contenant les données
temp1 = c(5.6, 6.1, 2.6, 1.5, 6.6, 5.8, 3.7, 3.2, 10.3, 7.8, 7.5, 7.7)
# Création d'une matrice DATA1 à partir d'un vecteur ; le
# remplissage se fait colonne par colonne (option par défaut)
# L'option nrow = 4 précise le nombre de lignes de la matrice
DATA1 = matrix(temp1, nrow = 4)
DATA1Important : une matrice est un objet possédant 2 dimensions (lignes/colonnes) dont TOUS les éléments sont de même type
Une fois la matrice créée, on doit rendre les données plus lisibles en identifiant les lignes par les noms des villes correspondantes et les colonnes par les trois premiers mois de l’année. Cette opération peut se faire à l’aide des 2 fonctions rownames et colnames :
# affectation de noms de villes aux lignes
rownames(DATA1) = c("Bordeaux", "Brest", "Clermont", "Grenoble")
DATA1
# affectation de noms de mois aux colonnes
colnames(DATA1) = c("Janv", "Fevr", "Mars")
DATA1
Exercice 2.1 Créer la matrice (que vous nommerez DATA2) contenant les données coloriées en \(\color{purple}{\textbf{violet}}\) ; vous prendrez soin de nommer correctement les lignes et colonnes
Manipulation de matrices
On considère la matrice ‘DATA1’ :
Janv Fevr Mars
Bordeaux 5.6 6.6 10.3
Brest 6.1 5.8 7.8
Clermont 2.6 3.7 7.5
Grenoble 1.5 3.2 7.7Ci-dessous quelques exemples de manipulation des éléments de la matrice :
DATA1[1, 1]
DATA1[3, 2]
DATA1[1:3, 1:2]
DATA1[c(1,4), c(1,3)]
DATA1[1, ]
DATA1[, 2]
DATA1[c(2,4), ]
DATA1[, 2:3]
DATA1[-1, ]
DATA1[, -1]
DATA1[-(2:4), -c(1,3)]# sélection d'éléments à partir des noms de lignes ou colonnes
DATA1["Clermont", "Janv"]
DATA1[, "Janv"]
DATA1["Clermont", ]
DATA1[1:2, "Fevr"]Changement d’un ou plusieurs élément(s) d’une matrice
Que se passe-t-il si on affecte à un élément de la matrice un objet d’un autre type?
On peut faire les opérations arithmétiques usuelles (addition, soustraction, multiplication, division) entre 2 matrices de même taille. Par exemple, si on veut comparer les températures des villes ligne à ligne entre Bordeaux (resp. Brest, Clermont et Grenoble) et Lille (resp. Lyon, Marseille et Montpellier), il suffit de taper la commande
Janv Fevr Mars
Bordeaux 3.2 3.7 4.3
Brest 4.0 2.5 0.1
Clermont -2.9 -2.9 -2.5
Grenoble -4.1 -3.5 -2.2Dès qu’une valeur est négative, cela signifie que la ville indiquée est plus froide que celle qui lui correspond. Par exemple, ici Grenoble est bien plus froide que Montpellier sur les mois de janvier, février et mars.
On peut faire les opérations arithmétiques usuelles entre 1 matrice et 1 nombre réel. Par exemple, on peut calculer la moyenne des températures pour DATA1 et la soustraire directement à DATA1 :
Janv Fevr Mars
Bordeaux -0.1 0.9 4.6
Brest 0.4 0.1 2.1
Clermont -3.1 -2.0 1.8
Grenoble -4.2 -2.5 2.0Dans ce cas, la moyenne est automatiquement soustraite à chaque élément de DATA1.
Remarque : les valeurs négatives identifient les villes dont les températures sont en dessous de la moyenne
Opérateurs logiques et matrices
Janv Fevr Mars
Bordeaux 5.6 6.6 10.3
Brest 6.1 5.8 7.8
Clermont 2.6 3.7 7.5
Grenoble 1.5 3.2 7.7DATA1 == 5.8
DATA1 <= 5.8
NEWDATA1 = DATA1
NEWDATA1[NEWDATA1 <= 5.8] = 0
NEWDATA1
DATA1[row(DATA1) > col(DATA1)]
Exercice 2.2 Créer une nouvelle matrice NEWDATA2 obtenue en affectant la chaîne de caractères ‘> 4’ aux températures de DATA2 strictement sup. à 4
Centrer un tableau de données
Centrer un tableau de données est une opération commune en statistique. Elle consiste à soustraire à chaque colonne sa moyenne. Le nouvelle matrice ainsi créée est telle que la somme de chaque colonne est nulle. Les fonctions colMeans et sweep permettent de réaliser facilement le centrage d’un tableau de données :
Exercice 2.3 Vérifier que la somme de chaque colonne de DATA1C est bien égale à zéro puis centrer le tableau DATA2
2.5 Dataframe : une structure de données très utile
Pour rappel, tous les éléments d’une matrice sont de même type. Or, lorsqu’on traite un tableau de données, il est courant d’observer à la fois des variables quantitatives et qualitatives. En conséquence on doit être capable de gérer dans un tableau des éléments de différents types (numériques, chaînes de caractères, etc). La structure dataframe de R permet de créer de tels objets.
A titre d’exemple, prenons le tableau qui décrit 4 caractéristiques des 8 planètes de notre système solaire :
- type de planète (Terrestre ou Géante gazeuse)
- diamètre de la planète relativement à celui de la Terre
- vitesse de rotation de la planète relativement à celle de la Terre
- La planète possède-t-elle des anneaux? (TRUE or FALSE)
| nom | type | diametre | rotation | anneaux |
|---|---|---|---|---|
| Mercury | Terrestre | 0.382 | 58.64 | FALSE |
| Venus | Terrestre | 0.949 | -243.02 | FALSE |
| Earth | Terrestre | 1.000 | 1.00 | FALSE |
| Mars | Terrestre | 0.532 | 1.03 | FALSE |
| Jupiter | Géante gazeuse | 11.209 | 0.41 | TRUE |
| Saturn | Géante gazeuse | 9.449 | 0.43 | TRUE |
| Uranus | Géante gazeuse | 4.007 | -0.72 | TRUE |
| Neptune | Géante gazeuse | 3.883 | 0.67 | TRUE |
Création d’un dataframe
Étape 1 : construction des 4 vecteurs correspondants aux 4 variables
nom = c("Mercury", "Venus", "Earth", "Mars", "Jupiter", "Saturn", "Uranus", "Neptune")
type = c("Terrestre", "Terrestre", "Terrestre", "Terrestre", "Géante gazeuse", "Géante gazeuse", "Géante gazeuse", "Géante gazeuse")
diametre = c(0.382, 0.949, 1, 0.532, 11.209, 9.449, 4.007, 3.883)
rotation = c(58.64, -243.02, 1, 1.03, 0.41, 0.43, -0.72, 0.67)
anneaux = c(FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE)Étape 2 : pour construire un dataframe, on utlise la fonction R data.frame()
Il suffit de passer en argument les vecteurs que l’on vient de créer :
nom type diametre rotation anneaux
1 Mercury Terrestre 0.382 58.64 FALSE
2 Venus Terrestre 0.949 -243.02 FALSE
3 Earth Terrestre 1.000 1.00 FALSE
4 Mars Terrestre 0.532 1.03 FALSE
5 Jupiter Géante gazeuse 11.209 0.41 TRUE
6 Saturn Géante gazeuse 9.449 0.43 TRUE
7 Uranus Géante gazeuse 4.007 -0.72 TRUE
8 Neptune Géante gazeuse 3.883 0.67 TRUEExercice 2.4 Le tableau ci-après est extrait de The movies database. Il fournit pour 7 films (sortie en 2015) son budget (en millions de dollars US), revenue (recettes en millions de dollars US), title (titre du film), main_actor (l’act.eur.rice principal.e du film), les genres et enfin l’evaluation (note fournie par le public)
| budget | revenue | title | main_actor | genres | evaluation |
|---|---|---|---|---|---|
| 150 | 1514 | Jurassic World | Chris Pratt | Action/Adventure/SF/Thriller | 6.5 |
| 150 | 378 | Mad Max : Fury Road | Tom Hardy | Action/Adventure/SF/Thriller | 7.1 |
| 135 | 533 | The Revenant | Leonardo DiCaprio | Western/Adventure/Thriller | 7.2 |
| 108 | 595 | The Martian | Matt Damon | Drama/Adventure/SF | 7.6 |
| 175 | 854 | Inside Out | Amy Poehler | Comedy/Animation/Family | 8.0 |
| 245 | 881 | Spectre | Daniel Craig | Action/Adventure/Crime | 6.2 |
| 15 | 37 | Ex Machina | Alicia Vikander | Drama/SF | 7.6 |
Construisez un dataframe que vous nommerez movies_df contenant l’ensemble de ces données
Sélection des éléments d’un dataframe
Reprenons l’exemple des planètes :
| nom | type | diametre | rotation | anneaux |
|---|---|---|---|---|
| Mercury | Terrestre | 0.382 | 58.64 | FALSE |
| Venus | Terrestre | 0.949 | -243.02 | FALSE |
| Earth | Terrestre | 1.000 | 1.00 | FALSE |
| Mars | Terrestre | 0.532 | 1.03 | FALSE |
| Jupiter | Géante gazeuse | 11.209 | 0.41 | TRUE |
| Saturn | Géante gazeuse | 9.449 | 0.43 | TRUE |
| Uranus | Géante gazeuse | 4.007 | -0.72 | TRUE |
| Neptune | Géante gazeuse | 3.883 | 0.67 | TRUE |
On peut sélectionner de différentes façons ses éléments (comme pour les objets de type matrix) :
planetes_df[1, 2]
planetes_df[1:3, 2:4]
planetes_df[, 1]
planetes_df[-1, ]
planetes_df[, -2]
planetes_df[-(1:4), -c(2,5)]planetes_df[, "nom"]
planetes_df[diametre > 1, "nom"]
subset(planetes_df, subset = anneaux)
subset(planetes_df, subset = diametre < 1)
Exercice 2.5 En reprenant le dataframe ‘movies_df’, créer un nouveau dataframe en sélectionnant uniquement les films dont le budget est supérieur ou égal à 140 millions USD
Une fonctionnalité supplémentaire liée aux dataframe est l’accès “facilité” aux variables avec le symbole $. Il suffit de taper dans la console le nom du dataframe suivi de $ (les noms des variables sont proposés dans un menu sur lequel il suffit de cliquer pour les sélectionner)
Fonctions utiles (summary, head, tail, View, etc)
Lorsqu’on dispose de grands jeux de données (c’est le cas de celui concernant le box-office dont est extrait l’exemple où envion 10000 films sont référencés), il est utile de disposer d’outils pour explorer le fichier données et s’approprier son contenu. Pour cela, il existe diverses fonctions R :
summary(planetes_df)
head(planetes_df)
tail(planetes_df)
View(planetes_df)
colSums(planetes_df[, 3:4])
colMeans(planetes_df[, 3:4])
Exercice 2.6 Transformer la variable ‘type’ contenue dans le dataframe ‘planetes_df’ en facteur puis afficher son résumé
2.6 Listes d’objets
Dans la syntaxe de R, une liste est une super structure de données capable d’inclure des objets de nature différente : vecteurs, matrices, dataframes et même listes.
Création d’une liste
La fonction R list() permet de créer une liste. Par exemple, à partir des données sur les planètes de notre système solaire,
| nom | type | diametre | rotation | anneaux |
|---|---|---|---|---|
| Mercury | Terrestre | 0.382 | 58.64 | FALSE |
| Venus | Terrestre | 0.949 | -243.02 | FALSE |
| Earth | Terrestre | 1.000 | 1.00 | FALSE |
| Mars | Terrestre | 0.532 | 1.03 | FALSE |
| Jupiter | Géante gazeuse | 11.209 | 0.41 | TRUE |
| Saturn | Géante gazeuse | 9.449 | 0.43 | TRUE |
| Uranus | Géante gazeuse | 4.007 | -0.72 | TRUE |
| Neptune | Géante gazeuse | 3.883 | 0.67 | TRUE |
on peut créer une liste des planètes de type Terrestre de la façon suivante :
anneaux = "non"
noms = c("Mercury", "Venus", "Earth", "Mars")
DiamEtRot = matrix(c(0.382, 0.949, 1, 0.532, 58.64, -243.02, 1, 1.03), nrow = 4)
rownames(DiamEtRot) = noms
colnames(DiamEtRot) = c("diamètre", "rotation")
# création de la liste à partir des objets "Anneaux", "noms" et "DiamEtRot" :
planeteTerrestre = list(anneaux = anneaux, planètes = noms, Diamètre_Rotation = DiamEtRot)
planeteTerrestrePour que cette liste planeteTerrestre soit plus lisible, on a rajouté des labels (i.e. noms) aux différents éléments qui la composent (“anneaux” pour anneaux, “planètes” pour noms et “Diamètre_Rotation” pour DiamEtRot).
Exercice 2.7 Créer une liste que vous nommerez planeteGeanteGaz similaire pour les planètes de type Géante gazeuse
Création d’une liste de listes
À partir des deux listes précédentes (planeteTerrestre et planeteGeanteGaz), il est facile de les fusionner en construisant une liste de listes :
Sélection d’éléments d’une liste
Une façon de sélectionner les éléments d’une liste est d’utiliser le double crochet [[ ]] en indiquant la position de l’élément à sélectionner. Si les composantes de la liste possèdent un nom, on peut de façon équivalente indiquer son nom à la place de sa position ; on peut aussi remplacer [[ ]] par $ (comme dans un dataframe) :
2.7 Connaître la structure d’un objet : fonction str()
On a vu précédemment que la structure d’un objet peut être sophistiquée. Il est donc utile d’avoir une fonction qui nous permette de décrire la structure d’un objet R. C’est le rôle de la fonction str() (abbréviation de structure) :
2.8 Chargement de tableaux de données (individus x variables)
Un tableau de données standard fournit en lignes les individus et en colonnes les variables. On parle alors de tableaux individus/variables. Ces tableaux de données se présentent sous la forme d’un fichier de données. Les formats (c’est-à-dire la façon dont les données sont organisées dans le fichier) les plus simples et transportables sont les formats textes avec des extensions de type .txt ou .csv (Comma-Separated Values) pour les plus communs.
Remarque : il est possible de charge des fichiers de données plus complexes à l’instar de ceux produit par des tableurs plus évolués comme Excel.
Méthode 1 : importation sous R d’un fichier de données local
Un fichier de données local est un fichier contenant des données présent physiquement sur un support local (typiquement votre disque dur). La fonctionnalité Import Dataset en haut à gauche dans RStudio permet d’importer sous R un fichier local. Il suffit de cliquer dessus (ce qui ouvre un menu) puis de cliquer à nouveau sur l’item From Text (base)…
.png)
pour pointer directement sur le fichier à importer. Une fenêtre s’ouvre automatiquement et vous invite à sélectionner le fichier de données. Une fois le fichier choisi, une fenêtre d’importation s’ouvre vous proposant différentes options de format
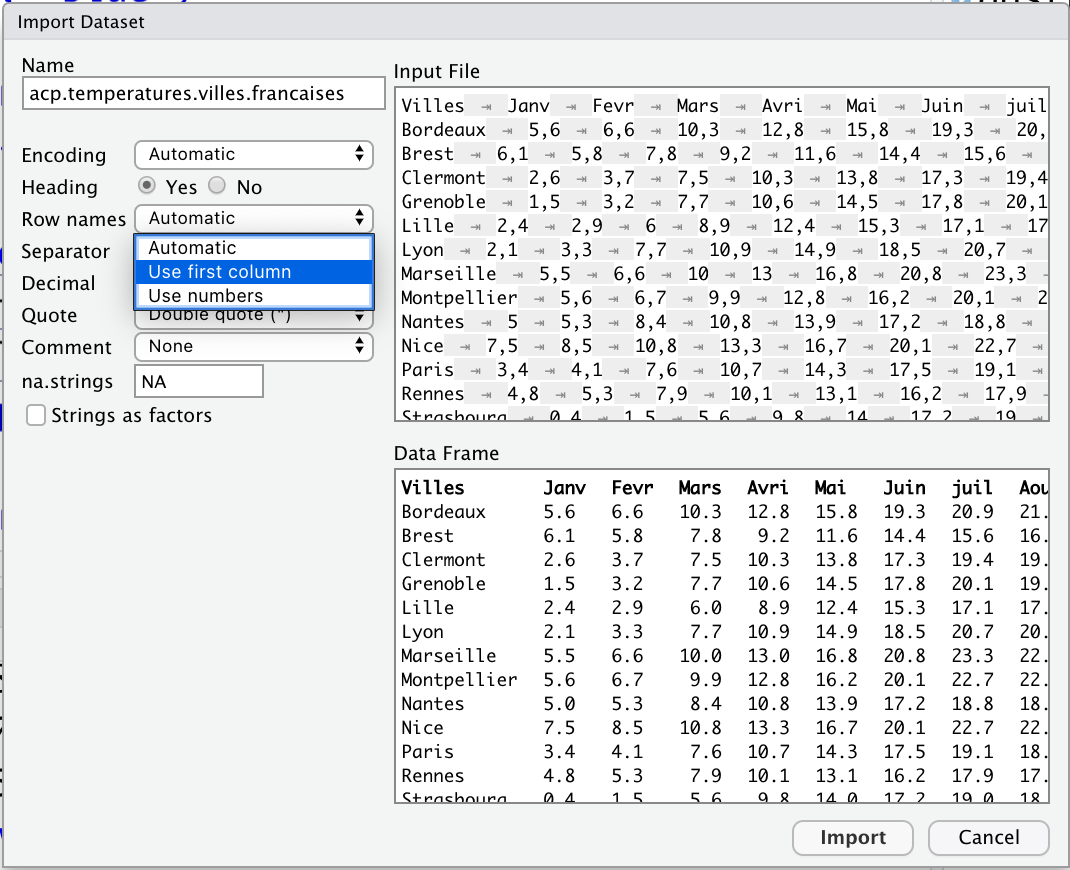 Les individus sont ici des villes françaises. La première colonne fournit les noms de villes ; on peut les utiliser pour nommer les individus (lignes). Pour cela, il suffit de sélectionner l’option Use first column (traduction utiliser la première colonne) en face de Row names (traduction noms de ligne). Si tout se passe bien, le format des données est automatiquement reconnu et il suffit d’appuyer sur le bouton Import (R exécute dans la console le code permettant de charger les données tout en les visualisant avec la fonction R View).
Les individus sont ici des villes françaises. La première colonne fournit les noms de villes ; on peut les utiliser pour nommer les individus (lignes). Pour cela, il suffit de sélectionner l’option Use first column (traduction utiliser la première colonne) en face de Row names (traduction noms de ligne). Si tout se passe bien, le format des données est automatiquement reconnu et il suffit d’appuyer sur le bouton Import (R exécute dans la console le code permettant de charger les données tout en les visualisant avec la fonction R View).
Exercice 2.8 Répondez aux questions suivantes :
Télécharger le fichier acp-temperatures-villes-francaises.txt disponible en ligne à l’adresse https://www.math.univ-toulouse.fr/~ferraty/DATA/acp-temperatures-villes-francaises.txt dans un répertoire de votre choix
Afficher un résumé de ce tableau de données
À l’aide de la fonction rowMeans de R et en extrayant correctement les données utiles, déterminer la ville la plus froide sur les 3 mois d’hiver (Décembre, Janvier et Février) ainsi que la ville la plus chaude toujours sur les 3 mois d’hiver
Même question pour les 3 mois d’été (Juin, Juillet et Août)
Méthode 2 : importer directement sous R depuis une URL
Une URL est un anglicisme désignant l’adresse d’une ressource sur internet. Si on connaît le format du fichier (présence ou non de labels pour les individus, présence ou non de labels pour les variables, séparateur de champs, symbole indiquant la décimale), il est possible de l’importer directement sous R sans le sauvegarder physiquement en local. Il suffit d’utiliser la fonction read.csv() avec en argument l’URL et diverses options caractérisant le format du fichier.
Important : pour pouvoir utiliser cette méthode, il faut être capable de visualiser le contenu du fichier à importer afin de compléter correctement les options de format (le fichier doit être édité avec un éditeur de texte basique qui permette de voir les séparateurs de champs)
Une fois le format du fichier bien identifié, on peut l’importer à l’aide de la fonction read.csv()
TEMP = read.csv("https://www.math.univ-toulouse.fr/~ferraty/DATA/acp-temperatures-villes-francaises.txt", header = TRUE, sep = "\t", dec = ",", row.names = 1)
View(TEMP)Ces différentes options de format sont les suivantes :
l’option header = TRUE indique que la 1ère ligne fournit les noms de variables
l’option sep = “\t” indique que le séparateur de champs est une tabulation
l’option dec = “,” indique que la virgule “,” symbolise la décimale dans un nombre
l’option row.names = 1 indique que la 1ère colonne fournit le nom des individus (lignes du tableau)
Remarque : si on ne connaît pas à l’avance le format du fichier, il est préférable d’utiliser la méthode 1
Exercice 2.9 Répondez aux questions suivantes :
Importer directement sous R le fichier girondeL1.csv disponible en ligne à l’adresse https://www.math.univ-toulouse.fr/~ferraty/DATA/girondeL1.csv sachant que :
- le séparateur de champs est une virgule “,”
- le symbole précisant la décimale un point “.”
- la 1ère ligne contient les noms des variables
- la 1ère colonne contient les noms des communes de la Gironde
Visualiser l’objet ainsi créé puis afficher un résumé de ce dataframe
Exécuter les commandes suivantes :
GIRONDE_sAF = read.csv("https://www.math.univ-toulouse.fr/~ferraty/DATA/girondeL1.csv", header = TRUE, sep = ",", dec = ".", row.names = 1, stringsAsFactors = TRUE)
summary(GIRONDE_sAF)En comparant le résumé de GIRONDE avec celui de GIRONDE_sAF que remarquez-vous?